인공지능/computer vision
Audio Reactive styleGAN (pending)
우연구
2022. 8. 12. 10:28
- git clone & run docker container & requirements
git clone https://github.com/JCBrouwer/maua-stylegan2
NV_GPU=1 nvidia-docker run --name bernice-audio-reactive -it -v $(pwd):/workspace -v $(readlink -f disk1):/disk1 nvcr.io/nvidia/pytorch:21.09-py3 /bin/bash
pip install -r requirements.txt
2. get the sources
https://loader.to/ko24/youtube-wav-converter.html
YouTube MP3 Playlist Downloader Online - Loader.to
Download YouTube Playlists in MP3 and other formats online for free using Loader.to!
en.loader.to
3. run
python generate_audiovisual.py --ckpt "/disk1/zzalgun/pretrained_models/4555kimg_8x8.pt" --audio_file "/disk1/audio/James-Blake_CMYK.wav" --channel_multiplier=1 --G_res=256
*error
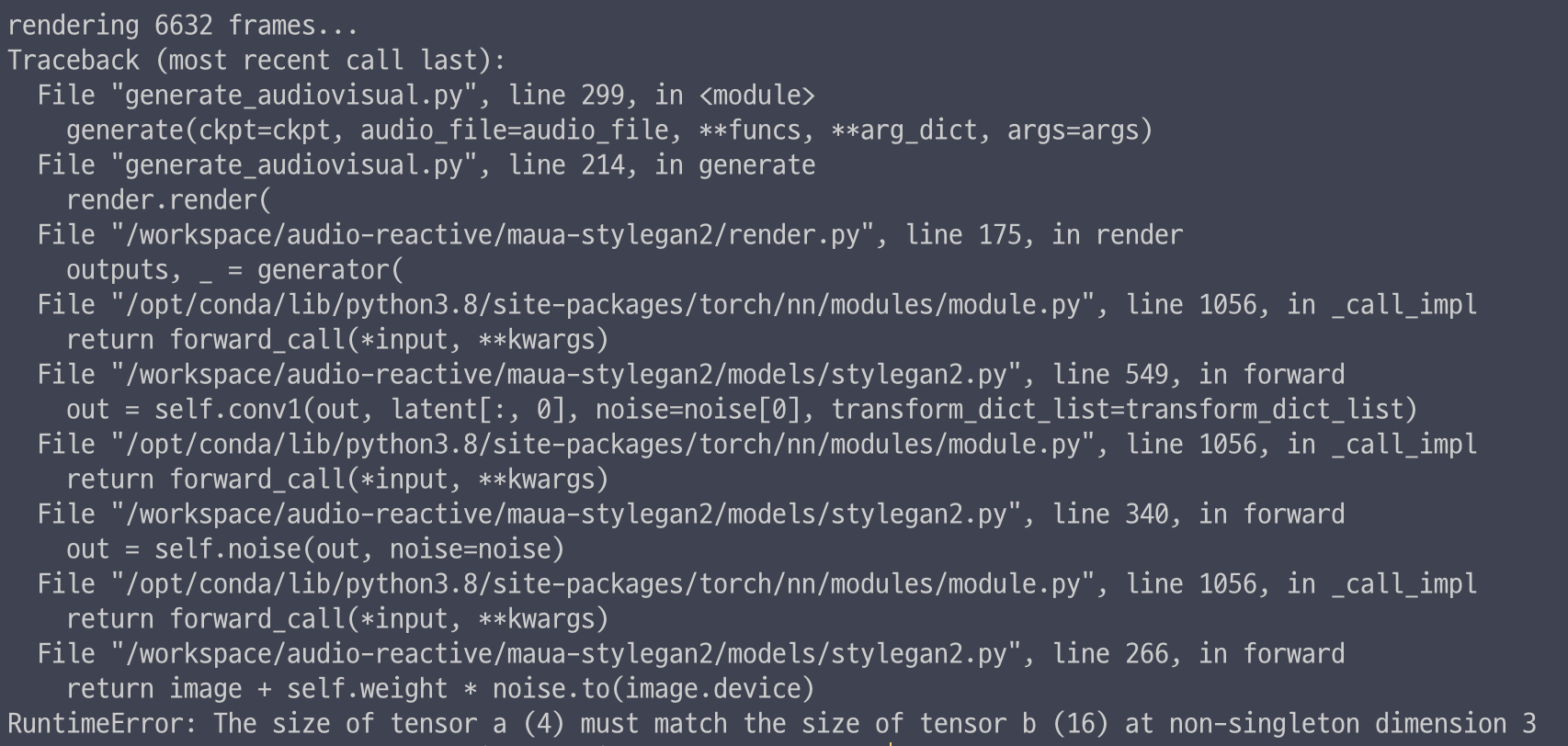
RuntimeError: The size of tensor a (4) must match the size of tensor b (16) at non-singleton dimension 3
- image 사이즈 torch.Size([8, 512, 4, 4])
- noise 사이즈 torch.Size([8, 1, 16, 16])
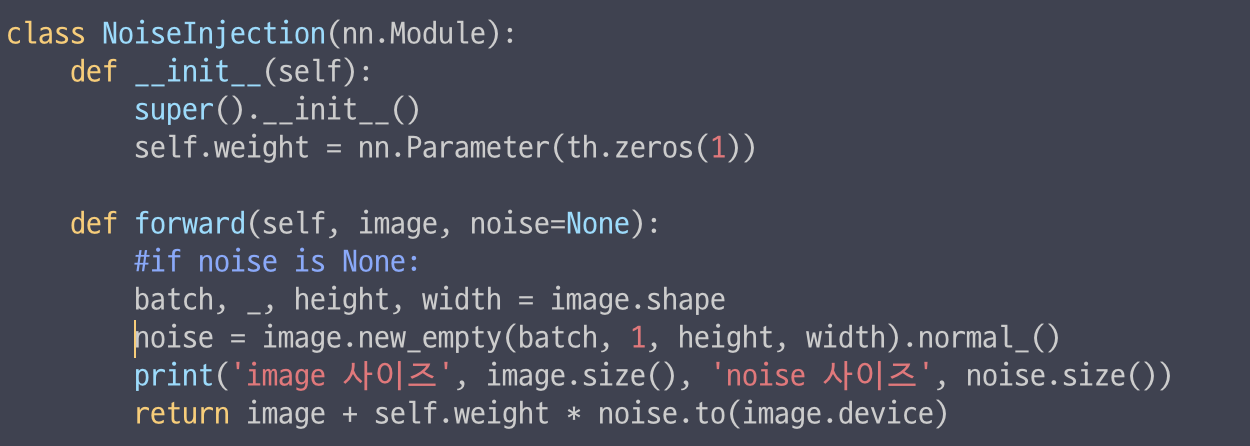
이렇게 수정했을 때 결과물은 생성이 되는데 화면이 없음
ffhq 모델로 재시도했으나 동일한 에러
python generate_audiovisual.py --ckpt "/disk1/zzalgun/pretrained_models/ffhq-256-config-e-003810.pt" --audio_file "/disk1/audio/James-Blake_CMYK.wav" --channel_multiplier=1 --G_res=256
--out_size 에 따라 noise 사이즈가 달라지는 거 보니까 output 크기 관련 문제인 것 같다