Single Number Evaluation Metric
to set up a single real number evaluation metric for your problem
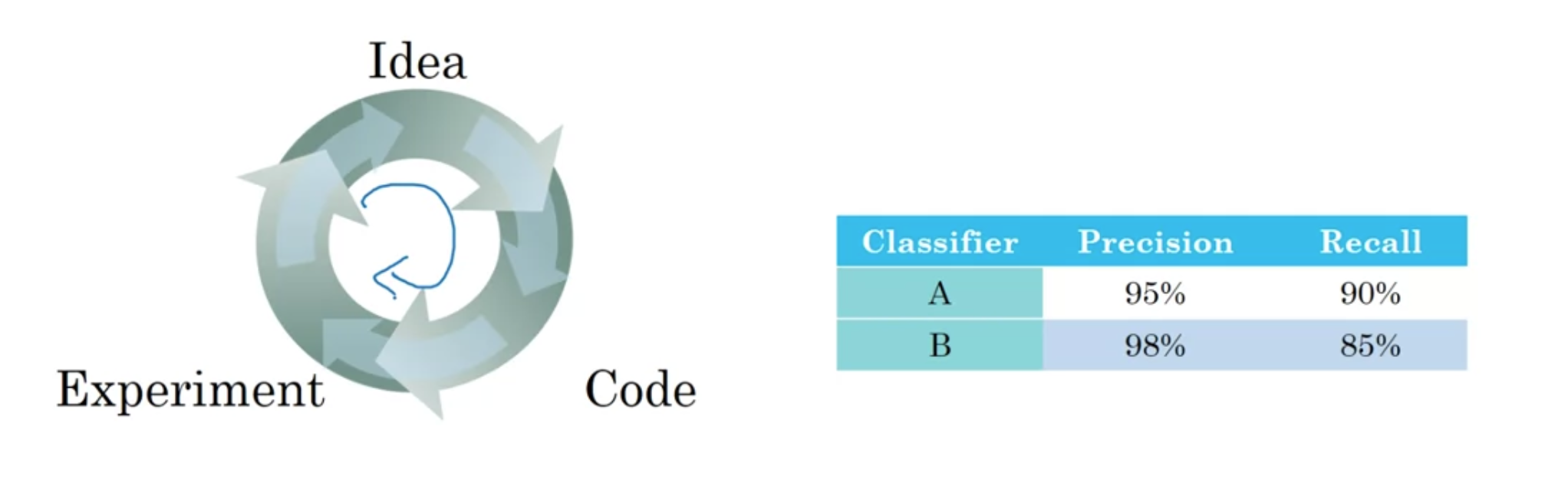
Precision : 고양이라고 분류했을 때 실제로 고양이일 확률 95퍼센트
Recall : 고양이 이미지 중에서 몇 퍼센트를 고양이로 분류했을까
Precision과 Recall 간의 trade-off가 있을 수 있음
Precision이 좋은 모델 A, Recall이 좋은 모델 B 중에서 뭐가 더 좋을까? 오직 두 개의 evaluation metric을 가지고 좋은 모델을 선정할 수는 있을까?
--> Precision과 Recall을 합친 F1 Score : "Average of $P$(Precision) and $R$(Recall)" , "Harmonic Mean"
$$\frac{2}{\frac{1}{P} + \frac{1}{R}}$$
well defined Dev Set (이것을 가지고 precision과 recall을 계산하게 됨) + single (real) number of eval metric --> iterating을 스피드업!

이럴 때 average를 계산함으로써 성능이 좋은 모델을 빠르게 선정할 수 있음
Satisficing and Optimizing Metric

정확도와 러닝타임을 하나의 evaluation metric으로 합치기
$$cost = accuracy - 0.5 \times runningTime$$
하지만 정확도와 러닝타임을 linear weighted sum과 같은 수식으로 합치는 건 좀 억지 같을지도 ...
이건 어떨까?
- maximize accuracy
- subject to running time $\leq$ 100 ms
이 경우에 정확도는 optimizing metric, 러닝타임은 satisficing metric이 됨 - 조건만 만족하면 OK
--> 만약에 $N$개의 metric을 고려하고 있다면, 그 중의 $1$개를 optimizing 으로 하고, $N-1$개는 satisfincing으로 하는 게 좋음
--
wakewords/trigger words의 예 (hey siri)
정확도(trigger words 를 불렀을 때 작동할 확률)와 False Positive(부르지 않았을 때 작동하는 경우) 를 합치는 방법
- maximize accuracy
- subject to 24시간마다 최대 한번의 false positive
Train/Dev/Test Distributions
dev set (= hold out cross validation set)

dev set과 test set이 다른 분포 --> 좋지 않은 예시
따라서 전체 데이터셋에서 randomly shuffle into dev/test set

이때 dev set과 test set은 동일한 분포에서 와야 함
Size of the Dev and Test Sets
데이터가 비교적 적은 예전에는 train:dev:test = 60:20:20 식으로 하는 것이 국룰이었음
그러나 데이터 사이즈가 훨씬 커진 지금은 98:1:1 정도면 충분

최종 모델의 성능이 얼마나 좋은지 정확한 척도가 필요한 게 아니라면, test set이 너무 클 필요는 없음
어떤 경우에는 최종 모델의 전체적인 성능에 대해 high confidence가 필요하지 않을 수도 있음
그렇게 되면 train/dev set만 필요 (추천하는 방식은 아님)

train/test split 하곤 했는데.. 이것이 결국 train/dev set 임
When to Change Dev/Test Sets and Metrics?

모델A의 evaluation metric이 더 좋지만 부적절한 이미지를 더 가지고 있다면? 기업 및 유저 입장에서 모델B가 적절한 모델이라고 볼 수 있음
Error(예측값과 라벨값이 일치하지 않는 횟수를 카운트):
$$\frac{1}{m_{dev}}\sum_{i=1}^{m_{dev}}I\{y_{pred}^{(i)} \neq y^{(i)}\}$$
이러한 evaluation metric의 문제점: 선정적인 이미지에 대해서도 일관적으로 계산
따라서 가중치를 더할 수 있음
$$w^{(i)} =\begin{cases}1 & x^{(i)}\ is\ non-porn\\10 & x^{(i)}\ is\ porn\end{cases} $$
$$\frac{1}{\sum_{i}w^{(i)}}\sum_{i=1}^{m_{dev}}w^{(i)}I\{y_{pred}^{(i)} \neq y^{(i)}\}$$
선정적인 이미지에 대한 에러에 10배의 가중치를 부여
이를 위해서는 dev/test 셋에서 선정적인 이미지에 대해 라벨링을 진행해야.
--> "defining a new evaluation metric"
이 또한 orthogonal한 접근이라고 볼 수 있는데 두 과정을 별개로 진행한다고 보면 됨

(1) 모델을 평가할 metric 을 어떻게 정의할 것인가에 대해서만 이야기하는 knob <-- "place the target"
(2) 이 metric에 어떻게 적용할 것인가를 별도로 고려하는 knob <-- "how to aim at this target accurately"(가중치를 부여하는 식으로 metric을 수정할 수도 있고)

training/dev/test 셋 모두 고품질의 고양이 사진이었는데, 실제 입력되는 유저의 고양이 이미지는 흐릿하고 보다 다양한 모양이이서 오히려 dev/test error가 높았던 모델B가 더 적합함
--> 이러한 경우에는 metric을 바꾸거나 dev set을 교체하자
'인공지능 > DLS' 카테고리의 다른 글
| [3.2.] Error Analysis (0) | 2022.07.18 |
|---|---|
| [3.1.] Comparing to Human-level Performance (0) | 2022.07.18 |
| [3.1.] Introduction to ML Strategy (0) | 2022.07.17 |
| [2.3.] Introduction to Programming Frameworks (0) | 2022.07.13 |
| [2.3.] Multi-class Classification (0) | 2022.07.13 |