Speech Recognition
[Speech Recognition Problem]
input $x$ : audio clip - air pressure against time
output $y$ : transcript
전처리 : spectrogram 생성 (시간 x requencies x energies)
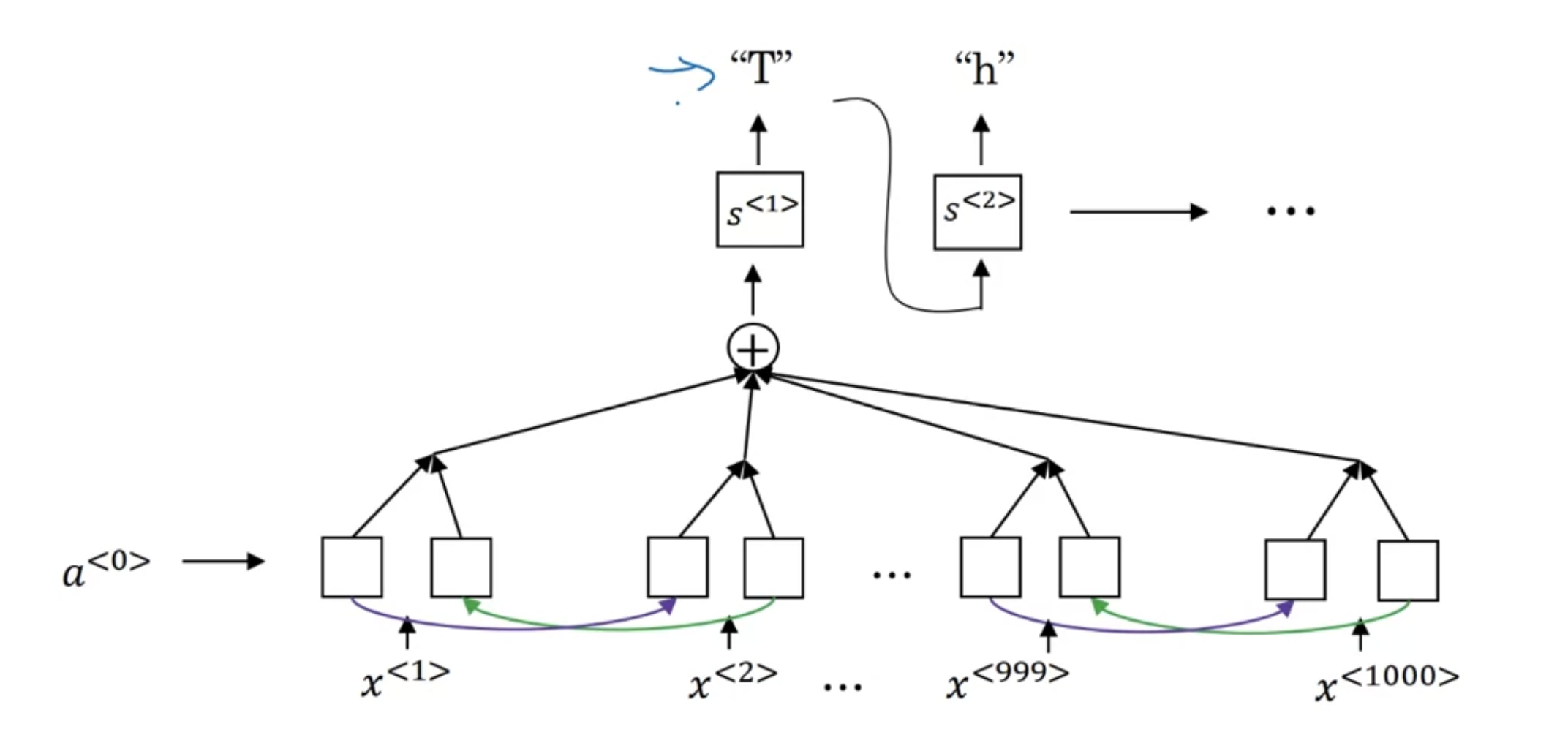
[Attention model for speech recognition]
[CTC cost for speech recognition]
(connectionist temporal classification)

- input과 output의 길이가 같은 RNN 신경망을 구성하낟
- speech recognition에서는 input time step 이 매우 커질 수 있는데, 초당 100 헤르츠짜리 음성 10초면 1000 스텝이 됨
- 실제로 output이 1000글자가 되지는 않을 텐데, 어떻게 할까?
t t t _ h _ e e e _ _ _ \n _ _ _ q q q _ _
basic rule : collapse repeated characters not seperated by "blank"
위에서 '_' 가 "blank"이고, space('\n')와는 다름
"blank"를 포함해서 1000개 output 을 만들어내면 실제로는 19개인 output을 구성할 수 있음
Trigger Word Detection

음성 데이터를 input으로 하고, 0, 1 라벨을 output으로 하는 RNN 모델
음성 데이터에서 trigger word가 끝나는 순간을 라벨 1로 함
단점? 불균형한 학습셋 (대부분이 0)
'인공지능 > DLS' 카테고리의 다른 글
| [5.4.] Transformers (0) | 2022.08.14 |
|---|---|
| [5.3.] Various Sequence To Sequence Architectures(2) (0) | 2022.08.13 |
| [5.3.] Various Sequence To Sequence Architectures(1) (0) | 2022.08.11 |
| [5.2.] Applications Using Word Embeddings (0) | 2022.08.11 |
| [5.2.] Learning Word Embeddings: Word2vec & GloVe (0) | 2022.08.09 |