머신러닝의 기초, numpy
1. 1. Numpy란?
- Numerical Python. 행렬 연산이나 다차원 배열(array) 연산을 편리하게 처리할 수 있게 하는 라이브러리입니다.
- 파이썬의 기본 list보다 빠르고, 적은 양의 메모리로 연산합니다.
- 차원이 다른 행렬끼리 계산할 수 있는 '브로드캐스트'를 지원합니다.
1.1. 1-1. np.array 연산
1.1.1. 1) 형태 확인하기
matrix1 = np.array([[1, 2], [3, 4]])
matrix2 = np.array([[5, 6], [7, 8]])
print(matrix1.shape)
print(matrix2.shape)Out: (2, 2)
두 배열 모두 (2, 2) 형태 입니다.
1.1.2. 2) 연산하기 - 배열끼리 연산
matrix1 + matrix2 # 행렬끼리 더하기Out:
[[ 6 8]
[10 12]]
1.1.3. 3) 연산하기 - 모든 요소에 1 더하기
matrix1 + 1 # 행렬 모든 요소에 1 더하기Out:
[[2 3]
[4 5]]
배열끼리 더하거나, 배열의 모든 요소에 int를 더할 수 있습니다.
다음으로, 같은 내용을 list로 수행해보기로 합니다.
1.2. 1-2. list 연산
1.2.1. 1) 형태 확인하기
list1 = [[1, 2], [3, 4]]
list2 = [[5, 6], [7, 8]]
print(len(list1))
print(len(list1[0]))Out :
2
2
list는 shape attribute가 없기 때문에, 전체 요소의 len를 구한 다음 첫번째 요소인 리스트의 len을 구했습니다.
1.2.2. 2) 연산하기 - 리스트끼리 연산
list1 + list2Out: [[1, 2], [3, 4], [5, 6], [7, 8]]
단순히 리스트끼리 더하면 두 리스트의 요소들을 합친 하나의 리스트가 됩니다.
list_result = []
# 행렬 계산 위해 원소의 수만큼 for문을 돌려야 함
for i in range(len(list1)):
temp = []
for j in range(len(list1[i])):
temp.append(list1[i][j] + list2[i][j])
list_result.append(temp)
print(list_result)Out: [[6, 8], [10, 12]]
array와 같이 계산하고 싶다면 for문을 돌려야 합니다.
1.2.3. 3) 연산하기 - 모든 요소에 1 더하기
list1 + 1TypeError: can only concatenate list (not "int") to list
단순히 리스트에 1을 더하는 것은 불가능합니다.
list_result = []
# 행렬 계산 위해 원소의 수만큼 for문을 돌려야 함
for i in range(len(list1)):
temp = []
for j in range(len(list1[i])):
temp.append(list1[i][j] + 1)
list_result.append(temp)
print(list_result)Out: [[2, 3], [4, 5]]
마찬가지로 for문을 돌려 각 요소에 1을 더해야 합니다.
2. 2. Numpy 의 자료형
- int(8bit, 16bit, 32bit, 64bit)
- uint(8bit, 16bit, 32bit, 64bit)
- float(16bit, 32bit, 64bit, 128bit)
- complex64, complex128
- bool
2.1. 2-1. 타입을 설정할 수 있습니다.
x = np.array([1, 2, 3, 4], dtype = np.float32)
y = np.array([1, 2, 3, 4], dtype = np.int32)
print(x.dtype)
print(y.dtype)Out:
float32
int32
2.2. 2-2. 타입을 확인할 수 있습니다.
x.dtypeOut: dtype('float32')
np.issubdtype(x.dtype, np.int32)Out: False
2.3. 2-3. 타입을 변환할 수 있습니다.
np.int32(x)Out: array([1, 2, 3, 4], dtype=int32)
3. 3. 다차원 배열 ndarray
N-dimensional array. 다차원 배열을 알아봅시다.
# 0차원
a = np.array(1)
print(a.shape) # 배열의 구조
print(a.ndim) # 배열의 차원
print(a.size) # 배열의 원소 개수Out:
()
0
1
차원이 없는 경우입니다.
# 1차원
a = np.array([1])
print(a.shape)
print(a.ndim)
print(a.size, '\n')
b = np.array([1, 2])
print(b.shape)
print(b.ndim)
print(b.size)Out:
(1,)
1
1
(2,)
1
2
모두 1차원이지만 원소의 개수가 다릅니다.
# 그 이상의 차원
a = np.array([[1], [2], [3]])
print(a.shape)
print(a.ndim)
print(a.size, '\n')
b = np.array([[1, 2], [3, 4]])
print(b.shape)
print(b.ndim)
print(b.size, '\n')
c = np.array([[[1, 2]], [[3, 4]]])
print(c.shape)
print(c.ndim)
print(c.size)Out:
(3, 1)
2
3
(2, 2)
2
4
(2, 1, 2)
3
4
a, b는 2차원이고 c는 3차원입니다.
a는 요소가 하나씩 든 배열 세 개가 있습니다. => (3, 1)
b는 요소가 두 개씩 든 배열 두 개가 있습니다 => (2, 2)
요소들이 있는 가장 안쪽을 따질 때(1차원) + 그 요소의 묶음 개수를 따질 때(1차원) => 2차원
c는 요소가 두 개씩 든 배열이 있습니다. 그 배열이 하나씩 든 배열이 있습니다. 그러한 배열이 두 개씩 든 배열이 있습니다. => (2, 1, 2)
a = np.array([[[1], [2]], [[3], [4]], [[5], [6]]])
print(a.shape)
print(a.ndim)
print(a.size)Out:
(3, 2, 1)
3
6
요소가 한 개씩 든 배열. 그 배열을 두 개씩 가진 배열. 그 배열을 세 개씩 가진 배열. => (3, 2, 1)
첫번째 차원은 가장 바깥쪽 대괄호([]) 안 요소를 생각합니다.
두번째 차원은 그것의 첫번째 요소의 대괄호([])를 봅니다.
...
그래서 차원은 대괄호의 개수와 같습니다.
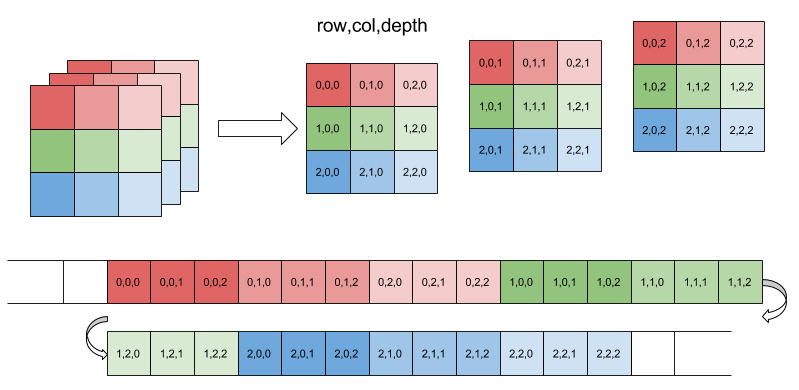
다음 이미지는 ndarray를 직관적으로 이해할 수 있도록 합니다.

세 ndarray를 파이썬으로 나타내보겠습니다.
first = np.array([7, 2, 9, 10])
print(first.shape)
print(first.ndim)
print(first.size, '\n')
second = np.array([[5.2, 3.0, 4.5],
[9.1, 0.1, 0.3]])
print(second.shape)
print(second.ndim)
print(second.size, '\n')
# 안 보이는 부분은 10이라고 가정
third = np.array([[[1, 2], [4, 3], [7, 4]],
[[2, 10], [9, 10], [7, 5]],
[[1, 10], [3, 10], [0, 2]],
[[9, 10], [6, 10], [9, 8]]])
print(third.shape)
print(third.ndim)
print(third.size)Out:
(4,)
1
4
(2, 3)
2
6
(4, 3, 2)
3
24
나중에 참고할 영상 www.youtube.com/watch?v=f5liqUk0ZTw&t=59s
4. 4. arange, linspace
arange는 파이썬 range와 거의 동일합니다.
* 오타주의보: arrange가 아니라 arange임을 기억합니다.
print(np.arange(10))
# 시작값, 끝값, 증갓값
print(np.arange(1, 10, 2))
print(np.arange(10, 1, -0.5))Out:
[0 1 2 3 4 5 6 7 8 9]
[1 3 5 7 9]
[10. 9.5 9. 8.5 8. 7.5 7. 6.5 6. 5.5 5. 4.5 4. 3.5 3. 2.5 2. 1.5]
linspace는 균일한 간격으로 리스트를 생성합니다. arange와 헷갈릴 수 있으니 아래와 같이 비교해볼 수 있습니다.
print(np.arange(1, 20, 5))
# 시작값, 끝값, 벡터크기
print(np.linspace(1, 20, 5))
print(np.linspace(1, 20, 5, endpoint=False))Out:
[ 1 6 11 16]
[ 1. 5.75 10.5 15.25 20. ]
[ 1. 4.8 8.6 12.4 16.2]
arange는 간격 크기를 인수로 주지만, linspace는 벡터 크기를 인수로 줍니다.
따라서 np.arange(1, 20, 5)는 1부터 시작해서 20까지 5 간격으로 [1, 6, 11, 16] 을 출력합니다.
반면 np.linspace(1, 20, 5)는 1과 20 사이를 균일한 간격으로 5개 출력하게 합니다. 즉 [ 1. 5.75 10.5 15.25 20. ]가 됩니다.
* endpoint: 끝값 포함 여부
4.1. arange와 linspace는 어떻게 다른가요?
그래프로 arange와 linspace를 비교해보겠습니다.
def f(x):
return x*(x-2)*(x+2)
for i in [arange_test, linspace_test]:
plt.scatter(i, f(i))
plt.grid()
plt.show()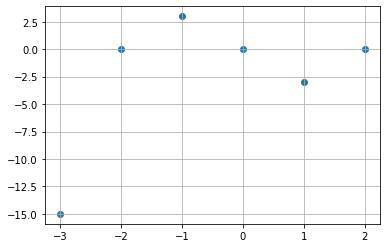
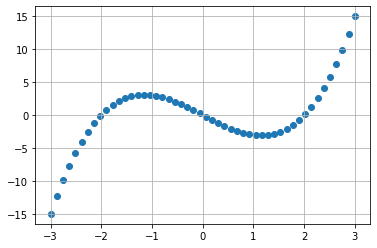
-2, 0, 2를 지나는 3차 그래프 위에 (-3, 3) 범위의 x좌표를 찍습니다.
scatter 그래프로 찍었을 때 왼쪽 arange는 여섯 개 점을 찍는 반면 오른쪽 linspace는 스무스한 모습으로 점을 찍습니다.
요컨대 arange는 원하는 정수만큼 일정 간격을 둔 정수 연속점을 생성할 수 있습니다. linspace는 비정수로 간격을 둡니다. (Use np.arange() if you want to create integer sequences with evenly distributed integer values within a fixed interval.
Use np.linspace() if you have a non-integer step size.)
5. 5. reshape
reshape을 통해 데이터를 유지하면서 차원의 형태를 변경할 수 있습니다.
이어서 작성할 것 ..
'인공지능 > 머신러닝-딥러닝' 카테고리의 다른 글
| 파이토치(PyTorch) 이해하기 with MNIST (0) | 2022.11.24 |
|---|---|
| 텐서플로우(TensorFlow)에서 파이토치(PyTorch)로 환승하기 (1) | 2022.11.24 |
| ASAM (pending) (0) | 2022.08.10 |
| tensorflow - 함수들 (0) | 2022.08.10 |
| Tensorflow (0) | 2022.08.10 |