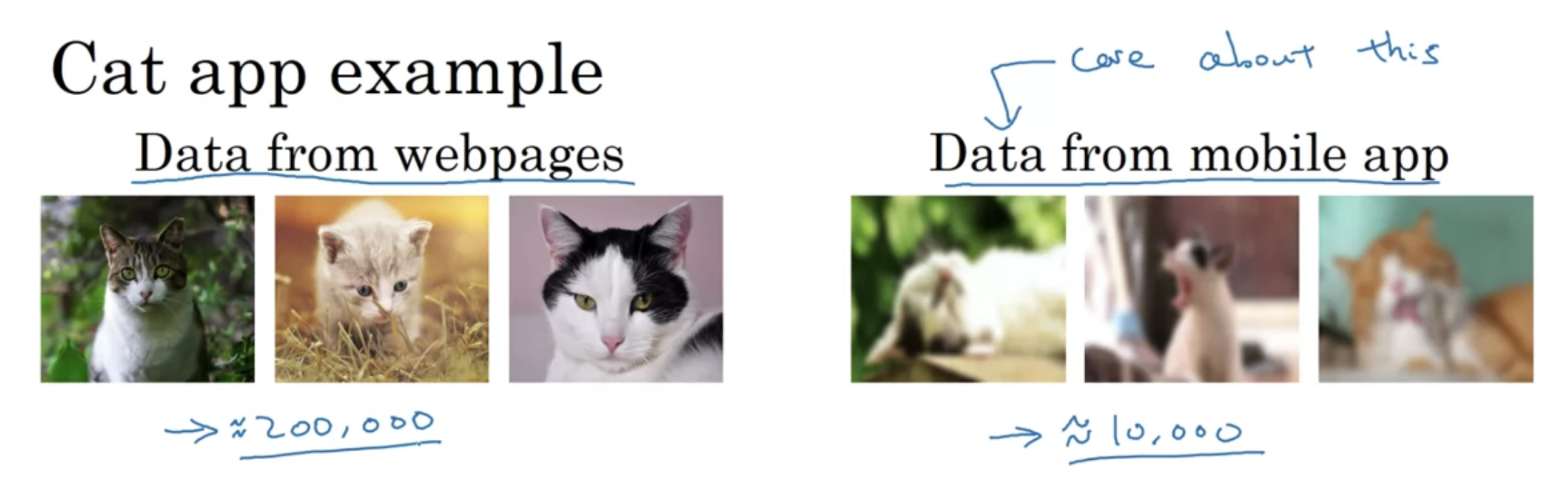
Training and Testing on Different Distributions
train과 test의 분포가 다를 때.
옵션1. 두 데이터를 섞고, randomly shuffle
- 장점: training/test가 동일한 분포에서 옴
- 단점: dev/test셋의 큰 비율이 여전히 webpage 샘플
--> 비추
옵션2. training set에 mobile app 데이터 일부를 주고, dev/test셋을 모두 mobile app 데이터로 꾸린다
- 장점: 원하는 target으로 설정할 수 있음
- 단점: training/test가 다른 분포에서 옴
--> 하지만 장기적으로는 나은 옵션
Bias and Variance with Mismatched Data Distributions

앞에서 살펴본 내용에 따르면 이는 variance 문제라고 볼 수 있지만... (training에 비해 dev 에러가 너무 큼)
training 과 dev 의 분포가 다를 경우에는 그렇게 단정지을 수 없음
만약 training set에 비해 dev set에 흐린 이미지가 더 많았던 거라면?
그러니까 두 가지 effect가 존재함: (1) 모델이 dev set을 보지 못하여 발생한 variance의 문제 & (2) 분포가 다른 문제
문제를 명확히 하기 위해 새로운 데이터셋을 정의해본다 ....
--> "training-dev set" : new subset of data, same distribution as training set, but not used for training
training/dev/test 으로 split한 다음, training set 을 shuffle 한 다음, training-dev set을 일부 따온다
이때 dev/test set이 동일한 분포를 가지듯, training/training-dev set은 동일한 분포를 가진다
training-dev set으로는 학습하지 않음 (모델이 training-dev set 은 보지 못함)

이 경우, variance 문제 (generalizing을 못하고 있음)

이 경우, variance 문제라기 보다는 "data mismatch problem"

이 경우 avoidable bias 문제

avoidable bias 높음 + data mismatch

avoidable bias / variance / data mismatch / degree of overfitting to dev set

위와 같은 독특한 경우도 있음 (dev/test set의 에러율이 더 낮은)

bias, variance, mismatch 문제 파악할 수 있고, 인간 레벨에서 rearview mirror speech가 더 어려운 과제임을 알 수 있음
Addressing Data Mismatch
완전 체계적인 해결 방법은 없지만 시도해볼 수 있는 것들 ...

dev set을 직접 들여다보기 (test set은 보지 않는다)

training에 데이터를 추가하는 식으로 비슷하게 만들기
training data와 dev data를 어떻게 비슷하게 만들 수 있을까?
[Aritifical data synthesis]

- 주의할 점: 만약 1000개의 음성 파일이 있고 1시간의 자동차 소음 파일을 합성한다면 모델이 그 자동차 소리에 overfit할 위험이 있음

- car recognition을 위해 CG로 자동차를 합성해 만듦
- 주의할 점: 사람 눈에는 그럴 듯해보이지만 알고보니 자동차 종류가 고작 20대였다면? 이 작은 subset에 overfit 해버릴 수 있음
'인공지능 > DLS' 카테고리의 다른 글
| [3.2.] End-to-end Deep Learning (0) | 2022.07.20 |
|---|---|
| [3.2.] Learning from Multiple Tasks (0) | 2022.07.20 |
| [3.2.] Error Analysis (0) | 2022.07.18 |
| [3.1.] Comparing to Human-level Performance (0) | 2022.07.18 |
| [3.1.] Setting Up your Goal (0) | 2022.07.17 |