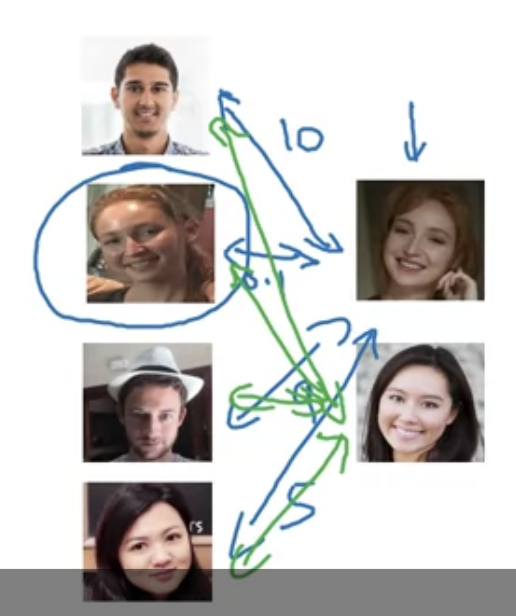
What is Face Recognition?
[Face verification vs. Face recognition]
Verification
- input image, name/ID
- Output whether the input image is that of the claimed person
- one-to-one problem
Recognition
- Has a database of K persons
- Get an input image
- Output ID if the image is any of the K persons (or "not recognized")
-> verification 정확도가 99% 면 괜찮은 정도인데, 만약 recognition 정확도가 99%라면 (그리고 K가 100명이라면) error가 1%나 된다(무슨 말인지 모르겠음..) 그러니 99% 보다 높은 정확도를 요구할 수 있음
One-shot Learning
Learning from one example to recognize the person again
떠올릴 수 있는 한 가지 방법: 주어진 이미지를 conv 신경망에 통과시켜서 5개 클래스(4명 혹은 모르는 사람) 확률을 출력하는 softmax 레이어 통과
-> training 샘플이 하나뿐일 때는 효과적이지 않다
-> recognize해야 하는 인원이 늘어날 때마다 매번 재학습해야 되는 것?
[Learning a "similarity" function]
$d(img1, img2)$ : degree of difference between images
- 비슷하면 작은 값, 다르면 큰 값 출력
If $d(img1, img2) \leq \tau$ --> 동일인물
If $d(img1, img2) > \tau$ --> 다른 사람
-> "face verification" with pairwise comparisons (데이터셋에 있는 모든 사람과 하나씩 비교)
-> 데이터베이스에 새로운 사람이 추가되어도 전부 재학습할 필요가 없음
Siamese Network
위에서 알아본 function $d$ : input two faces and tell you how similar or how different they are
[Siamese Network]
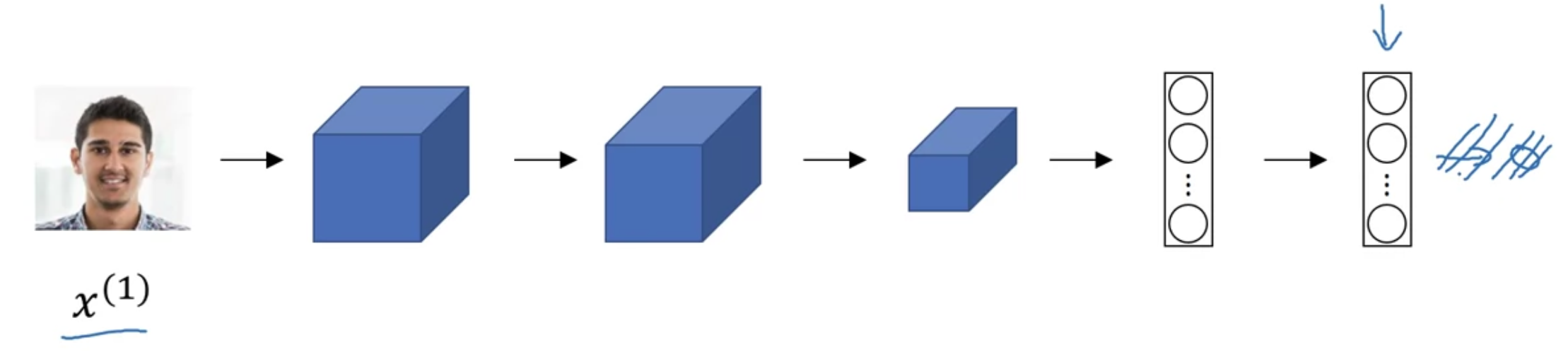
일반적인 conv 신경망에서 softmax 레이어를 제외하고 생각
softmax 에 입력하기 직전 128개 활성화값을 $f(x^{(1)})$이라고 부르기로 함 - "encoding of $x^{(1)}$"
입력된 이미지를 128개 값의 벡터로 re-representing 하는 것
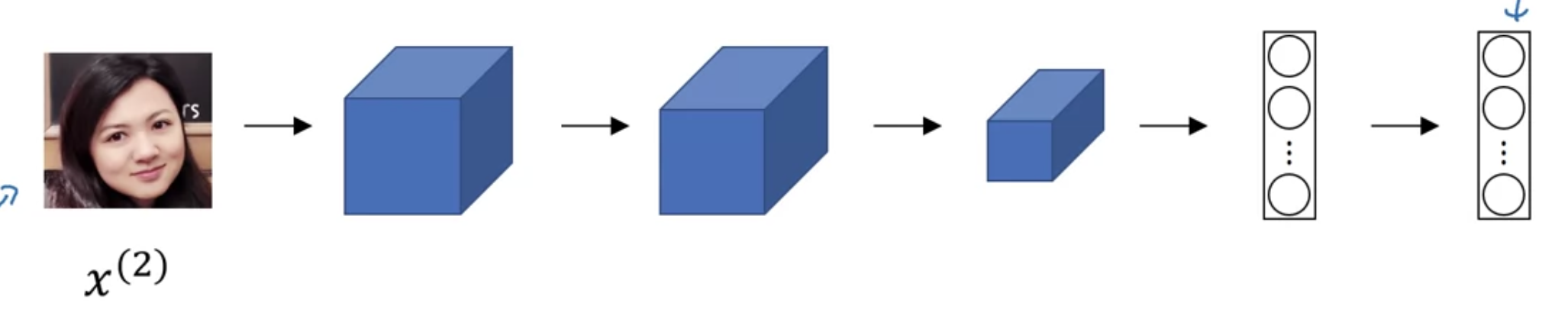
비교하고자 하는 이미지를 동일한 네트워크, 동일한 파라미터에 입력시켜서 128개 값의 벡터를 받아냄 --> $f(x^{(2)})$
$$d(x^{(1)}, x^{(2)}) = \parallel f(x^{(1)}) - f(x^{(2)}) \parallel ^{2}$$
-> 이러한 네트워크 구조를 "Siamese Network"라고 부른다
[Goal of learning]
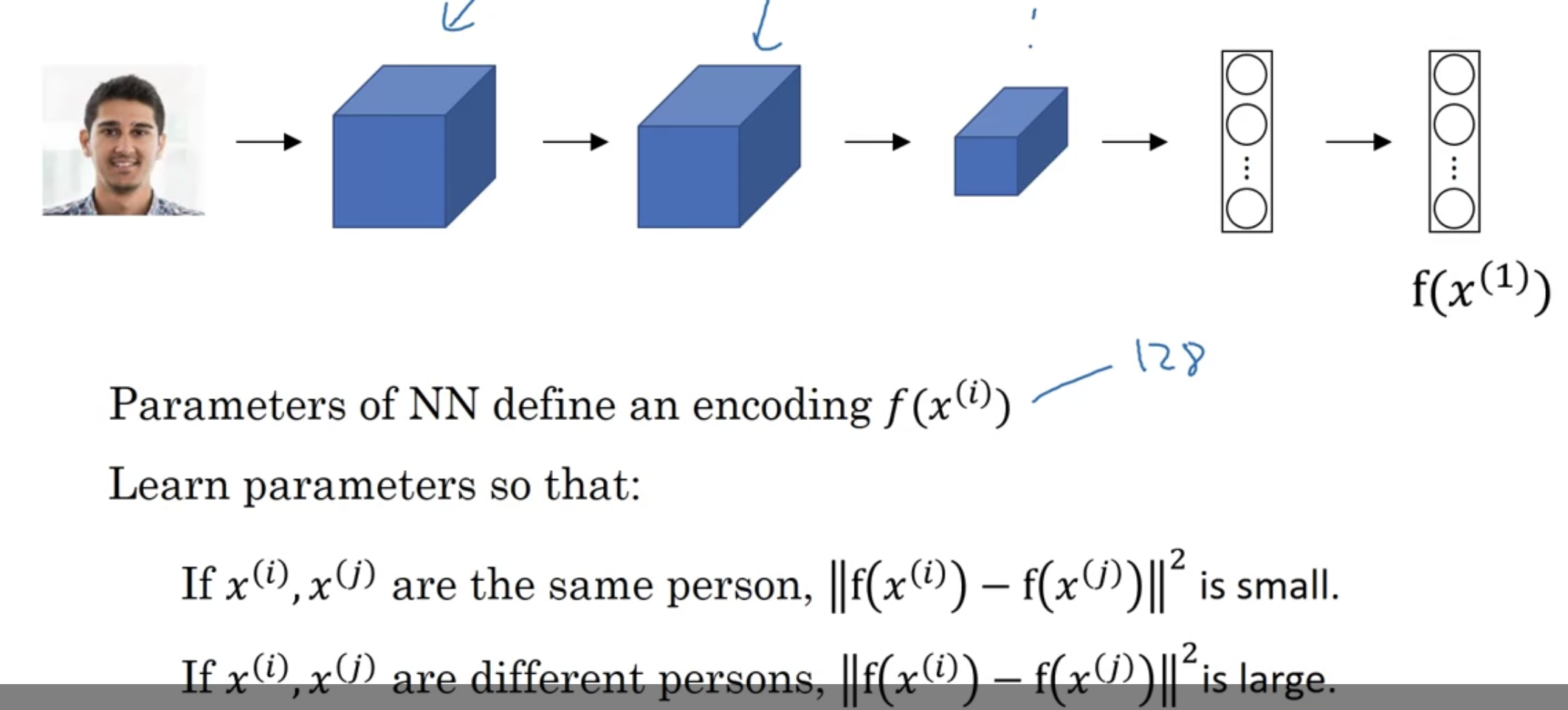
아래 두 조건이 만족되도록 back prop 실시
하지만 object function은?
Triplet Loss
신경망의 파라미터를 학습시키기 위해서는 여러 이미지를 동시에 보아야 한다


전자: 두 이미지는 동일인이므로 encode된 값이 유사해야 한다
후자: 값이 달라야 함
anchor 이미지($A$)와 positive($P$)/negative($N$) example을 비교 -> 세 개 이미지를 한번에 보는 셈(triplet)
$$\parallel f(A) - f(P) \parallel ^{2}\ \leq\ \parallel f(A) - f(N) \parallel ^{2}$$
$$\parallel f(A) - f(P) \parallel ^{2}\ - \parallel f(A) - f(N) \parallel ^{2} \leq\ 0$$
$\parallel f(A) - f(P) \parallel ^{2}$ 와 $\parallel f(A) - f(N) \parallel ^{2}$가 모두 $0$이 되면 위 식은 자명해져 버림
이는 모든 encoding 값이 동일하다는 것인데, 이것을 방지하기 위한 방법이 필요
위 식을 살짝 수정하여
$$\parallel f(A) - f(P) \parallel ^{2}\ - \parallel f(A) - f(N) \parallel ^{2} \leq\ 0 - \alpha$$
$0$보다 살짝 작기만 하면 된다
conventionally, 식은 이렇게 씀
$$\parallel f(A) - f(P) \parallel ^{2}\ - \parallel f(A) - f(N) \parallel ^{2} + \alpha \leq\ 0 $$
$$\parallel f(A) - f(P) \parallel ^{2}\ + \alpha \leq\ \parallel f(A) - f(N) \parallel ^{2}$$
여기서 $\alpha$는 "margin" 파라미터라고 부른다
$d(A, P) = 0.5$, $d(A, N) = 0.51$, $\alpha = 0.2$ 라면
$$0.5 + 0.2 \leq 0.51$$
$\alpha$가 없을 땐 식이 성립되는데, margin 파라미터를 추가함으로써 $d(A, N)$이 $d(A, P)$보다 훨씬 더 커지고 $d(A, P)$가 훨씬 작아져야 식이 성립하게 됨 (push them further away from each other)
[Loss function]
3개의 이미지 $A$, $P$, $N$가 주어졌을 때,
$$L(A, P, N) = max(\parallel f(A) - f(P) \parallel ^{2}\ - \parallel f(A) - f(N) \parallel ^{2} + \alpha, 0)$$
앞의 값이 $0$ 이하이면 loss 가 0인 것과 마찬가지이므로 max 함수 사용함
cost function:
$$J = \sum_{i=1}^{m}L(A^{(i)}, P^{(i)}, N^{(i)})$$
학습데이터로 1000명의 이미지 10000개가 있다면, 3개 셋트 ($A$, $P$, $N$) 를 고를 수 있어야 한다
또한 동일인 사진으로 이루어진 쌍 ($A$, $P$) 들이 필요하다 -> 동일인의 사진 여러 개가 필요
[Choosing the triplets $A$, $P$, $N$]
random하게 고르면 $d(A, P) + \alpha \leq d(A, N)$이 너무 쉽게 충족될 수가 있음
랜덤하게 선택된 $A$, $P$에 대해서 $d(A, N)$이 높은 값이 되기는 쉽다
Choose triplets that are "hard" to train on
$d(A, P) + \alpha \approx d(A, N)$일 때 더 잘 학습될 수 있음

Face Verification and Binary Classification
face recognition 시스템을 학습할 수 있는 또다른 방법

두 임베딩값을 입력하면 동일인인지 다른 사람인지 출력하는 logistic regression unit 을 활용 - 동일인이면 1, 아니면 0 출력
a way to treat face recognition as a binary classification problem - an alternative to the triplet loss
$$\hat{y} = \sigma(\sum_{k=1}^{128} w_{k} \mid f(x^{(i)})_{k} - f(x^{(j)})_{k} \mid + b )$$
- $f(x^{(i)})_{k}$ : 이미지 $x^{(i)}$의 encoding 벡터의 k번째 값
- 두 encoding 벡터 간 element-wise difference 의 절대값
- ... 를 logistic regression 식에 대입
- difference의 절댓값 대신에 chi-square similarity($\chi^{2}$)를 사용하는 방법도 있음:
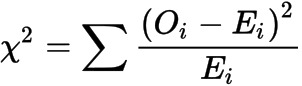
$$\hat{y} = \sigma(\sum_{k=1}^{128} w_{k} \frac{(f(x^{(i)})_{k} - f(x^{(j)})_{k})^{2}}{f(x^{(i)})_{k} + f(x^{(j)})_{k}} + b )$$
- 입력 $x$는 두 개의 이미지 쌍, $y$는 0 아니면 1
- siamese network이기 때문에 두 이미지가 통과하는 각각의 네트워크는 동일한 파라미터 가지고 있음
- 새로운 입력이 들어왔을 때, database 이미지에 대한 encoding 벡터값을 미리 저장해두고(pre-compute) 활용할 수 있다
[Face verification supervised learning]

'인공지능 > DLS' 카테고리의 다른 글
| [5.1.] Recurrent Neural Networks(1) (0) | 2022.08.02 |
|---|---|
| [4.4.] Neural Style Transfer (0) | 2022.08.02 |
| [4.3.] Detection Algorithms(3) (0) | 2022.08.02 |
| [4.3.] Detection Algorithms(2) (0) | 2022.08.01 |
| [4.3.] Detection Algorithms(1) (0) | 2022.07.28 |