
초록
최근 GAN 활용에 있어서 unconditional한 이미지 합성이 주목 받음. 학습된 GAN의 latent code로 이미지를 invert하는 과제가 매우 중요. 실제 이미지를 조작하고 네트워크가 학습한 semantics를 활용할 수 있음. 현재 invert 방식의 한계를 인지하고, 새로운 invert 전략을 제시하고자 함. iterative refinement (반복 세분화) 메커니즘을 도입하여, 현재의 encoder 기반 invert 방법론을 확장한 것임. 주어진 이미지의 latent code를 single pass로 직접 예측하는 대신에, encoder로 하여금 self-correcting(자가 수정) 방식으로 invert된 latent code의 현재 추정값에 대하여 잔차(residual)를 예측하도록 한다. residual-based encoder ‘ReStyle’은 무시해도 될 정도로 작은 inference 시간 증가와 함께 현재 SOTA encoder-based 방법론보다 개선된 accuracy를 이룬다. 본 논문에서는 ReStyle의 반복적인(iterative) 속성과 관련해 의미 있는 통찰을 찾기 위해 ReStyle의 행동을 분석한다. residual encoder의 성능을 평가하고, optimization-based 변환 방식과 SOTA encoder와 비교해 robustness를 분석한다.
Introduction
- 최근 (Style)GAN의 latent space에 의미 정보(semantic information)를 효과적으로 encoding하는 방법에 대해 연구가 이루어짐
- 실제 이미지를 편집하기 위해서는 먼저 해당 이미지를 styleGAN의 latent space로 변환해야 함
- pre-trained styleGAN 생성기에 통과시켰을 때 원본 이미지가 출력되는 latent code w를 구하는 것
- 이를 위해 주로 extension of W (denoted W+) 에 실제 이미지를 변환시켜왔음 (Image2StyleGAN 참고)
- 기존 연구들은 learning based 변환법을 탐구, encoder가 실제 이미지를 상응하는 latent code로 매핑하도록 학습시킴
- per-image latent vector optimization과 비교했을 때, encoder는 single forward pass로 이미지를 변환하기 때문에 훨씬 빠르고, 편집하기에 더 적합한 latent space 영역으로 수렴함(?)
- 하지만 복원 정확도에 있어서는 learning based 방법론과 optimization 방법론 사이에 큰 차이가 남아있음 (
encoder가 더 빠르고 편집에 용이하긴 한데, 정확도 측면에서는 optimization 방식이 유리
- single shot으로 정확하게 변환하기 어렵다는 사실을 인지하고, extended W+ StyleGAN latent space에 실제 이미지를 encoding하는 새로운 encoder based 변환 전략을 소개함
- single forward pass로 입력 이미지의 latent code를 inference하는 encoder-based 변환 방식과 다르게, 본 논문에서는 iterative feedback mechanism (반복적 피드백 메카니즘) 을 도입
- 원본 입력 이미지와 함께 이전 iteration의 출력을 encoder에 넣어줌으로써 여러 차례 forward pass를 실시
- 이전 iteration에서 얻은 정보를 활용하여 정확한 복원이 필요한 중요 영역에 집중할 수 있게 됨
- residual encoder는 현재 latent code와 새로운 latent code 간의 잔차(residual, offset)를 예측하도록 학습, 타겟 code를 향해 inversion을 점진적으로 수렴시킴
single forward pass 대신에 several forward pass 방식 사용
- 즉, pre-trained unconditional 생성기의 latent space 안에서 residual-based 방식으로 적은 횟수의 step을 수행하도록 학습하는 것
- ReStyle은 styleGAN inversion 과제에 있어서 다양한 encoder 아키텍처와 loss objectives에 적용될 수 있다는 점에서 포괄적
- ReStyle reconstruction
- inference 시간은 무시할 수 있을 정도로 조금 증가하며, 시간적 비용이 많이 드는 optimization-based inversion보다 여전히 빠른 속도
- 각 iterative feedback 스텝마다 이미지의 어떤 영역이 정제되는지 확인; coarse-to-fine
- 각 step마다 변화의 절대 크기(absolute magnitude)가 감소하는 것 확인; 예측된 잔차가 몇 번의 step만으로 수렴
- latent space manipulations, encoder boostrapping
Background and Related Works
- iterative refinement scheme
- https://diane-space.tistory.com/344 <Human Pose Estimation with Iterative Error Feedback> 부분 참고, iterative refinement for optical flow, object pose estimation, object detection, semantic segmentation …
- 실제 이미지의 learned inversion에 iterative refinement 적용한 것은 본 논문이 최초
- GAN Inversion
- GAN latent space의 semantic을 활용해 다양한 이미지 조작이 가능
- 방법1. 복원 오차를 최소화하는 방식으로 latent vector를 직접 optimize하는 방법; 복원 퀄리티는 좋지만 이미지당 수 분 소요
- 방법2. 주어진 이미지와 그것에 상응하는 latent vector를 직접 mapping하는 encoder를 디자인하는 방법; 순수 optimization보다는 효과적이지만 복원 퀄리티가 떨어지는 편
- 방법3. 이러한 trade-off의 밸런스를 맞추기 위해 하이브리드 접근법이 존재
- Latent Space Embedding via Learned Encoders
- 실제 이미지를 조작하기 위해 보통 “invert first, edit later” 방식 사용
- 최근에는 end-to-end 방식이 제안됨; 실제 이미지가 transformed latent code로 직접 encoded되고, 이후 목표하는 사진을 얻기 위해 생성기로 입력
- Latent Space Manipulation
- 이미지 조작을 위한 latent representation 통제 방법론
- 나이, 성별, 표정과 같은 다양한 속성에 해당되는 latent direction을 찾기 위해 fully-supervised approach가 사용됨 / unsupervised 방식도 사용됨
- latent space의 linear traversal(선형 순회)를 넘어서는 테크닉들
- pre-trained EDMM
- 생성기 weight의 eigenvector decomposition(고유값 분해)
- 타겟 속성에 conditioned된 flow를 정규화함으로써 non-linear path(비선형 경로)를 학습
- 입력 텍스트를 활용해서 CLIP 조작 https://brunch.co.kr/@advisor/33
Preliminaries
- Encoder-Based Inversion Methods
- GOAL : pre-trained styleGAN 생성기(G)의 latent space에 실제 이미지를 invert하는 encoder(E) 학습
- 입력 이미지 x가 있을 때, x ≈ ŷ 인 이미지 G(E(x)) = ŷ를 생성해야 함
- 기존 encoder-based inversion methods는 단순하게 E, G를 통과하는 single forward pass로써 ŷ를 계산
- E를 학습하기 위해 일련의 손실함수들을 도입
- 대부분 encoder-based 방법론들은 가중치를 반영해 pixel-wise L2 손실함수와 perceptual 손실함수 사용
- 최근 손실함수를 확장하고 identity 손실함수를 도입함으로써 인간 얼굴 도메인에서 개선된 복원을 이루어냄
- 이에 더해, 훈련 중 두 개의 regularization 손실함수를 도입하여 editablity를 개선시킴

Encoder Architecture
- ReStyle 전략을 SOTA encoder 인 pSp와 e4e에 적용하기로. 두 encoder는 ResNet 기반 위에 Feature Pyramid Network 을 적용해 세 개의 중간 단계에서 style feature를 추출함
- 이러한 계층적(hierarchical) encoder는 얼굴과 같이 잘 구조화된 도메인에서 well-motivated됨
- 얼굴 도메인에서는 입력이 세 레벨의 디테일로 나누어질 수 있음
- 해당 디자인에서는 덜 구조화된 multi-model 도메인도 무시할 만큼 작은 영향만 받음 - while introducing an increased overhead(오버헤드)
- ReStyle의 multi-step 특성이 복잡한 encoder 아키텍처에 대한 필요성을 완화시켜줌
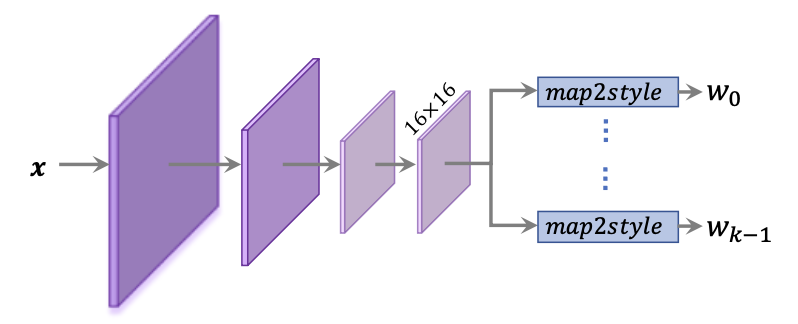
- 세 개의 중간 단계에서 style feature를 추출하기보다는, 모든 style vector를 마지막 16x16 피처맵에서 추출
- k개 스타일 입력이 있는 styleGAN 생성기가 있을 때, k개의 다른 map2style 블록(pSp)은 feature map을 down sample 하는 데 사용해서, 상응하는 512차원의 style 입력을 얻을 수 있음
<중략...>

'인공지능 > computer vision' 카테고리의 다른 글
| GAN 실험(1) - 주키즈 캐릭터 (0) | 2022.08.10 |
|---|---|
| few-shot GAN ada 이해하기 (0) | 2022.08.01 |
| p2S2p 이해하기 (0) | 2022.08.01 |
| styleGAN3 이해하기 (0) | 2022.08.01 |
| styleGAN2 이해하기 (0) | 2022.05.31 |