
초록
생성 모델(GAN)을 제한된 샘플(e.g. 10)로 이루어진 타겟 도메인에 학습시키는 것은 오버피팅으로 이어지기 쉬움. 본 논문에서는 pretraining에 많은 양의 소스 도메인을 활용하고, 소스에서 타겟으로 diversity information을 transfer함. 새로운 cross-domain distance consistency loss를 통해 소스 객체들 간의 상대적인 유사점과 차이점을 보존함. 오버피팅을 더욱 줄이기 위해 anchor-based 전략을 제시, latent space의 여러 영역에 걸쳐 다양한 수준의 realism을 조성하도록 함. photorealistic, non-photorealistic 도메인에서의 결과를 통해 질적, 양적으로 증명함 - 본 논문의 few-shot 모델이 자동적으로 소스와 타겟 도메인 간의 관련성(correspondence)을 포착하여 이전 방법론들보다 더욱 다양하고 실제적인 이미지들을 생성함
Introduction
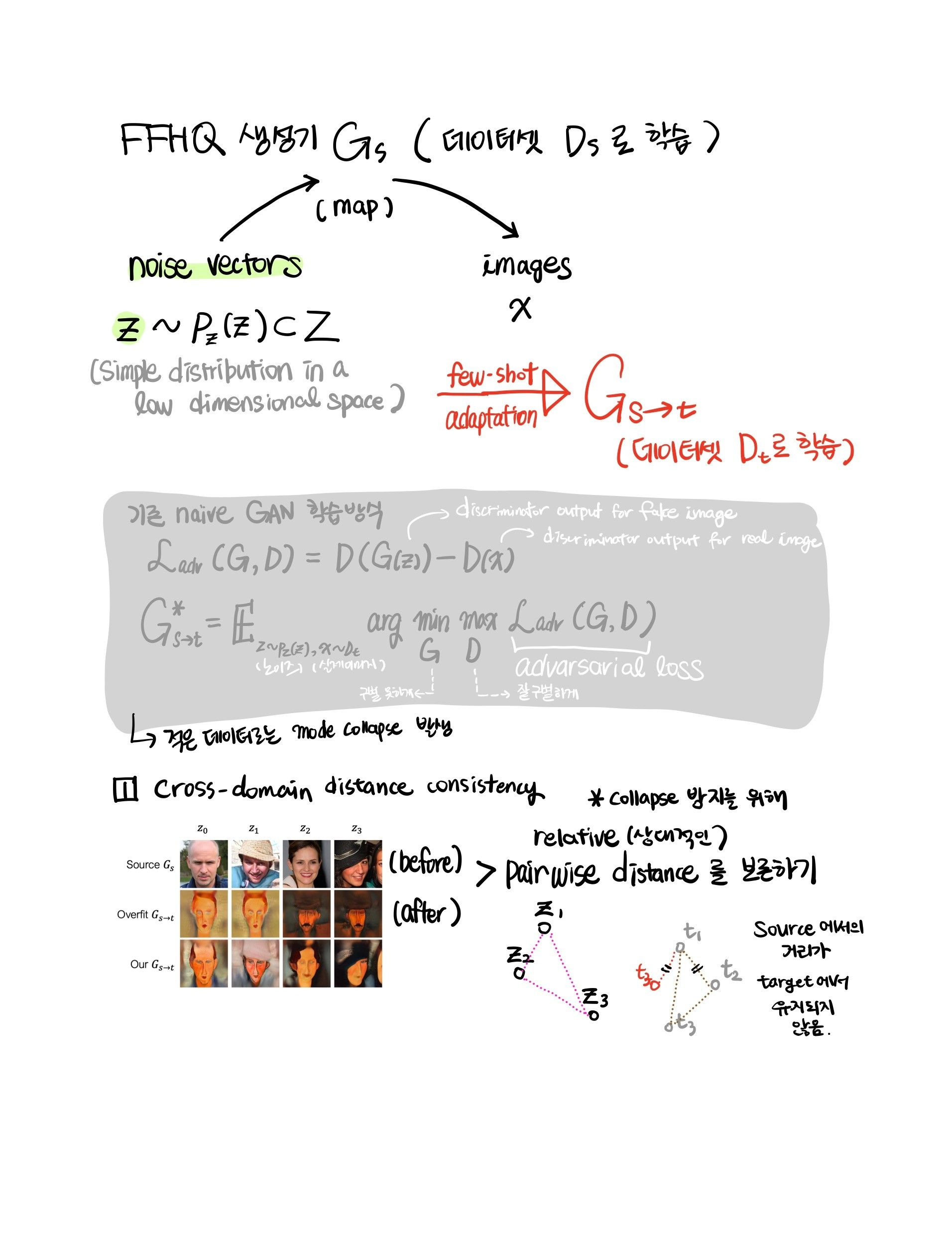
- 10개 샘플만을 가지고 해당 스타일의 이미지를 끝없이 생성하는 모델을 학습시킬 수 있을까? 현재 생성모델은 수천 장의 이미지를 필요로 함
- (바닥부터 학습시키는 방식을 대신하는) 전이학습 - 한정된 데이터를 다루는 GAN의 맥락에서 탐구되어 옴
- 대량의 데이터셋에 사전학습된 소스 모델로 시작하여 제한된 데이터의 타겟 도메인으로 적용(adapt)시키는데, 네트워크의 파라미터를 조금만 수정하여 최대한 많은 정보를 보존하거나 데이터 증강을 통해 학습 데이터를 합성, 증가시키는 식이었음
- 그러나 대부분 방법론들은 100장 이상의 학습 데이터가 존재할 때의 시나리오 - 사용하는 이미지의 양이 적어질 경우 오버피팅이 발생하거나 퀄리티가 좋지 않음
- 본 연구에서는 소스 도메인에서 다른 종류의 정보를 transfer 함, 즉, 각 이미지들이 어떻게 서로 연관되는지(how images relate to each other)
- 직관적으로 보았을 때, 모델이 소스 도메인의 객체들 간의 상대적인 유사점과 차이점을 보존할 수 있다면, 타겟 도메인에 adapt하면서 소스 도메인의 다양성을 물려받을(inherit) 수 있을 것
- 새로운 cross-domain distance consistency loss : adaptation 전후로 생성된 샘플을 쌍으로 거리를 계산하여, 이 분포에 나타나는 유사성을 강화함 (which enforces similarity in the distribution of pairwise distances of generated samples before and after adaptation)
- image-to-image 변환과 같은 domain adaptation 접근법과는 달리, 여기서는 이미지가 아니라 모델을 adapt 함
- 두 도메인 간의 structure-level alignment (구조 수준..)을 강화하면서 흥미로운 특징이 나타남
- (사람 얼굴과 캐리커쳐와 같이) 소스 도메인과 타겟 도메인이 연관되어 있을 때, 자동적으로 일대일 상관관계를 발견하고, 다양성과 실제성 측면에서 더욱 충실하게 실제 타겟 분포를 모델링할 수 있게 됨
- (자동차와 캐리커쳐와 같이) 두 도메인이 연관되어 있지 않을 때, 타겟 분포를 모델링할 수는 없었지만 여전히 흥미로운 부분적인(part-level) 상관관계를 발견하고 다양한 샘플을 생성하였음
- 소수의 학습 샘플은 근사하려는 타겟 분포의 small subset만을 이루므로, 두 가지 다른 방식으로 realism을 강화시킬 필요를 느꼈음
- 생성된 이미지들 간의 다양성을 너무 과도하게 penalize하지 않을 것
- 1) 실제 샘플 중 하나와 매핑되어야 하는 생성 이미지를 대상으로 image-level adversarial loss를 적용함
- 2) 다른 생성 이미지들에 대해서는 patch-level adversarial loss만 강화
- 이를 통해 생성된 샘플들의 small subset만 few-shot 학습 이미지들 중 하나처럼 보여져야 하고, 나머지는 patch-level texture만 포착하도록 강화됨
Related work
[Few-shot learning]
few-shot 이미지 생성은 소수의 학습 이미지에 과적합되는 것을 방지하면서 새로운, 다양한 샘플들을 hallucinate하는 것을 목표. 현존하는 연구는 주로 adaptation 파이프라인을 따르는데, 대량의 소스 도메인에 사전학습된 베이스모델을 더 적은 타겟 도메인에 adapt시키는 것. 적은 개수의 새로운 파라미터를 소스 모델에 임베딩하거나, 새로운 형태의 regularization을 통해 소스 모델의 파라미터를 직접 업데이트하는 것. 오버피팅을 방지하기 위해 데이터 증강을 사용하기도 하는데, extreme한 few-shot 환경(e.g., 10장 이미지)에서는 효과가 떨어짐. 이전 연구와 다르게 본 연구에서는 소스 도메인에서 타겟 도메인으로 ‘이미지들이 어떻게 서로 연관되는지’ transfer함으로써 소스 모델의 adaptation을 regularize, 매우 적은 샘플만 가지고도 그럴 듯한 생성 결과로 이어짐
[Domain translation]
소스 도메인에서 이미지를 변환하는 것은 더 많은 타겟 도메인 데이터를 생성하는 것에 대해 대안적인 접근법. 하지만 이러한 방법론은 소스 도메인, 타겟 도메인 모두에서 대량의 학습 데이터를 요구하며, few-shot 시나리오에 적합하지 않음. 최근 연구들은 content와 style 요소를 분리하도록 학습함으로써 이 문제를 다루고자 하나, 라벨링된 대량의 데이터가 필요함. 본 연구는 소스 도메인에서는 라벨링되지 않은 대량의 데이터에 접근이 가능하다고 가정하고 unconditional하게 타겟 도메인으로 adapt하는 것에 집중
[Distance preservation]
GAN 모델에서 mode collapse를 완화하기 위해 DistanceGAN은 입력쌍과 그에 상응하는 생성 출력쌍 사이 거리를 보존하는 방식을 제시함. 비슷한 전략이 uncoditional 혹은 conditional한 생성 태스크 모두에 적용됨 - 생성물의 다양성을 증가시키기 위해. 본 연구에서는 학습된 다양성이 소스 모델에서 타겟 모델로 물려지도록 목표하고, 이를 새로운 cross-domain distance consistency loss로 이뤄냄
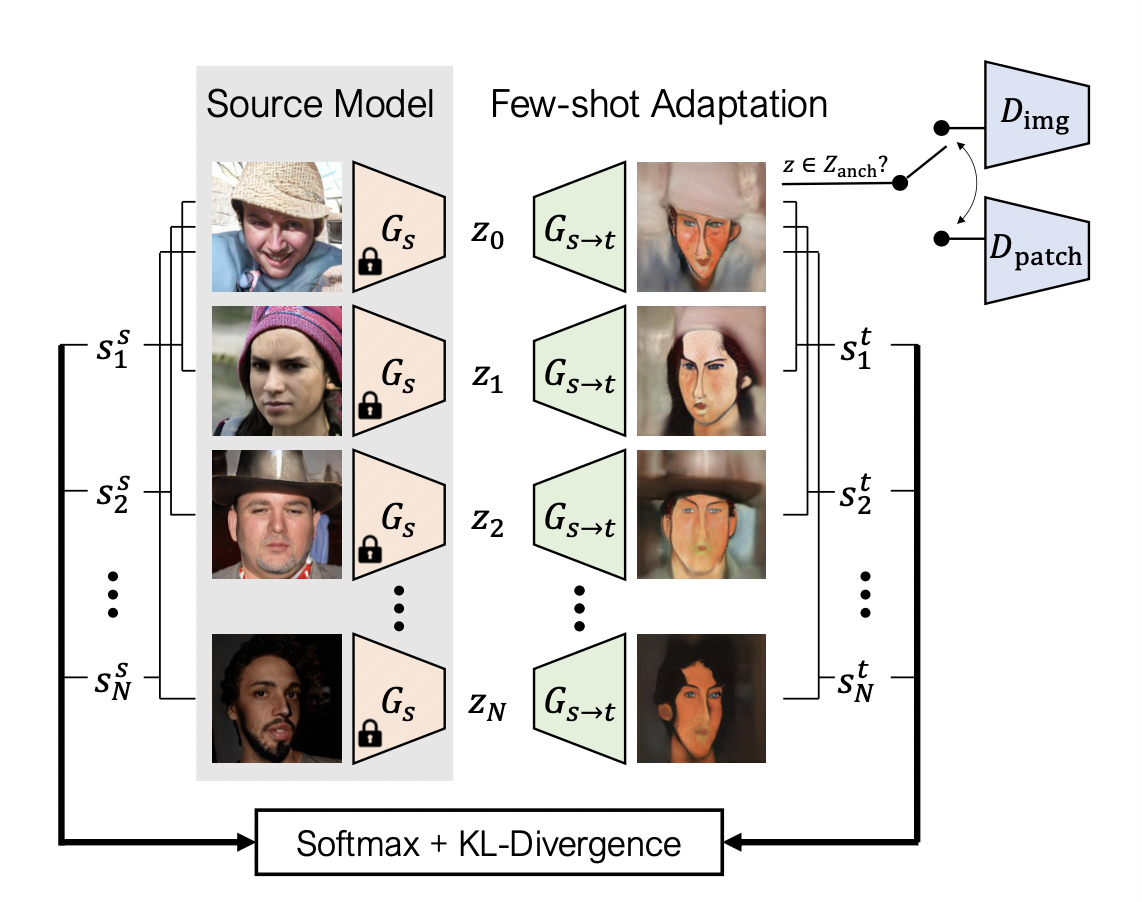
Approach
Cross-domain distance consistency
- adaptation 도중 발생한 오버피팅의 결과 : 소스 도메인 내 relative distance가 보존되지 않음
- → 가설 : adaptation 전후로 relative pairwise distances의 보존을 강화하면 mode collapse를 방지하는 데 도움이 된다
- N + 1 개로 이루어진 noise vector의 배치 하나( {zn}N0 )를 샘플링하여, feature space에서 pairwise 유사성들을 활용, 각 이미지별로 N-way 확률분포를 구성함

Relaxed realism with few examples
- 타겟 데이터의 크기가 매우 작을 때, “실제적인” 이미지를 구성하는 것에 대한 정의(definition)가 overconstrain 됨 - 판별모델이 few-shot 타겟 학습셋을 쉽게 암기할 수 있기 때문
- 소수의 학습 데이터는 원하는 분포의 작은 subset만을 이루고, 이 개념이 latent space까지 확대됨
- “anchor” 영역(Zanch ⊂ Z)을 새롭게 정의 : 전체 latent space의 subset을 이룸
- 이 영역 안에서 샘플링할 때 full image discriminator Dimg를 활용
- 이 영역 밖에서는 patch-level discriminator Dpatch를 사용해 adversarial loss를 강화
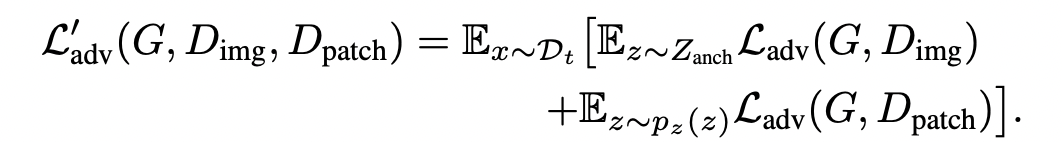
- anchor space를 정의하기
- k 개(학습 이미지와 같은 개수)의 랜덤 포인트를 선택하여 저장
- 이 고정된 포인트로부터 샘플링한 후 작은 가우시안 노이즈를 추가 (σ = .05)
- Dpatch를 더 큰 Dimg 네트워크의 subset이라고 정의함으로써 두 개의 판별기 간에 공유된(shared) weight를 사용; 입력 위 patch에 상응하는 internel activation을 사용
- 사이즈는 네트워크 아키텍쳐와 레이어에 따라 다름
- 효과적인 패치 사이즈는 22x22 ~ 61x61
Final Objective
- 목적 함수
- L`adv : 타겟의 appearance
- Ldist : 구조적 다양성을 보존하기 위해 소스 모델을 직접 활용
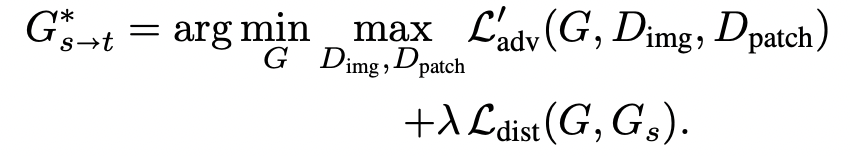
- patch 판별기는 이미지 구조에 있어서 additional freedom을 주고, adapted 생성기는 소스 생성기에서 도메인 구조를 빌려오도록 직접 incentivized됨
- cross-domain correspondences
We also investigate what kinds of correspondences emerge when the source and target domains are unrelated.
Experiments
(중략..)
[What role do different components of our method play?]
- Ldist을 제외했을 때 다양성이 줄어들어 생성 이미지들의 머리 구조와 헤어 스타일이 매우 비슷해짐
- Ldist을 사용하되
- 모든 생성 이미지에 대해 Dimg를 사용했을 때, part level에서 mode collapse가 발생하고 동일한 mode에서 조금씩 변형된 결과만 나타나는 현상
- 모든 생성 이미지에 대해 Dpatch를 사용했을 때, 다양성은 관찰되지만 퀄리티가 저하됨; discriminator가 온전한(complete) 캐리커처 이미지를 절대 볼 수 없기 때문에 결과적으로 캐리커처를 실제적으로 보이게 만드는 part-level 상관관계를 배우지 못함
- 최종 : part-level, image-level 에서 다양하면서 실제적인 이미지 생성
Analyzing source ↔ target correspondence
- 소스 도메인과 타겟 도메인 간 상관관계를 포착하여 adaptation 과정 중에 유지함
- 캐릭터 이미지와 사람 이미지는 어느 정도로 관련 있는 도메인이라고 볼 수 있을까?
- 관련된 소스/타겟 도메인
- 소스 도메인과 타겟 도메인이 유사한 semantic을 가지고 있을 때, 동일한 noise vector에서 생성된 이미지들은 각각 명확한 correspondence를 가지고 있음
- 관련없는 소스/타겟 도메인
- adaptations으로 타겟 분포를 정확하게 포착하지 못했음; 그러나 일정 part-level correspondences 가 나타나기도 함

Effect of target dataset size
- 1-shot : small variation
- 5-shot : diversity 증가, 스케치의 경우 distinct identity 표현
- 10-shot : more details, more divers
Conclusion and Limitations
- to adapt a pretrained GAN learned on a large source domain to a small target domain by discovering cross-domain correspondences
- 한계 존재: 예를 들어 few-shot 세트에 존재하는 색깔로 바뀌는 문제 - 소스와 타겟 도메인 간 더 적절한 correspondence를 발견할 필요가 있음



'인공지능 > computer vision' 카테고리의 다른 글
| GAN 실험(2) - layer swapping (0) | 2022.08.10 |
|---|---|
| GAN 실험(1) - 주키즈 캐릭터 (0) | 2022.08.10 |
| ReStyle 이해하기 (0) | 2022.08.01 |
| p2S2p 이해하기 (0) | 2022.08.01 |
| styleGAN3 이해하기 (0) | 2022.08.01 |