Published 2022. 8. 19. 19:46
1주차
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')
test_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])from tensorflow.keras.optimizers import RMSprop
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=0.001),
metrics=['accuracy'])history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=15,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
import numpy as np
from keras.preprocessing import image
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
x /= 255
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
if classes[0] > 0.5:
print("it's a dog")
else:
print("it's a cat")
visualization
import numpy as np
from tensorflow.keras.preprocessing.image import img_to_array, load_img
# Define a new Model that will take an image as input, and will output
# intermediate representatinos for all layers in the previous model after the first
successive_outputs = [layer.output for layer in model.layers[1:]]
visulaization_model = tf.keras.models.Model(inputs= model.input, outputs=successive_outputs)
img = load_img(img_path, target_size=(150,150))
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
x /= 255.0
successive_feature_maps = visualization_model.predict(x)
layer_names = [layer.name for layer in model.layers]
# display
for layer_name, feature_map in zip(layer_names, successive_feature_maps):
if len(feature_map.shape) == 4:
n_features = feature_map.shape[-1] # num of features
size = feature_map.shape[1] #feature map size
display_grid = np.zeros((size, size * n_features))
for i in range(n_features):
x = feature_map[0, :, :, i]
x -= x.mean()
x /= x.std()
x *= 64
x += 128
x = np.clip(x, 0, 255).astype('uint8')
display_grid[:, i*size : (i+1)*size] = x
scale = 20. / n_features
plt.figure(figsize=(scale*n_features, scale))
plt.imshow(display_grid)acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc)
plt.plot(epochs, val_acc)
과제
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
import matplotlib.pyplot as plt[데이터 다운로드]
# Define root directory
root_dir = '/tmp/cats-v-dogs'
# Empty directory to prevent FileExistsError is the function is run several times
if os.path.exists(root_dir):
shutil.rmtree(root_dir)
# GRADED FUNCTION: create_train_val_dirs
def create_train_val_dirs(root_path):
"""
Creates directories for the train and test sets
Args:
root_path (string) - the base directory path to create subdirectories from
Returns:
None
"""
### START CODE HERE
# HINT:
# Use os.makedirs to create your directories with intermediate subdirectories
# Don't hardcode the paths. Use os.path.join to append the new directories to the root_path parameter
os.makedirs(root_dir)
for sub in ['training', 'validation']:
sub_path = os.path.join(root_dir, sub)
os.makedirs(sub_path)
for s in ['cats', 'dogs']:
os.makedirs(os.path.join(sub_path, s))
### END CODE HERE
try:
create_train_val_dirs(root_path=root_dir)
except FileExistsError:
print("You should not be seeing this since the upper directory is removed beforehand")
# GRADED FUNCTION: split_data
def split_data(SOURCE_DIR, TRAINING_DIR, VALIDATION_DIR, SPLIT_SIZE):
"""
Splits the data into train and test sets
Args:
SOURCE_DIR (string): directory path containing the images
TRAINING_DIR (string): directory path to be used for training
VALIDATION_DIR (string): directory path to be used for validation
SPLIT_SIZE (float): proportion of the dataset to be used for training
Returns:
None
"""
### START CODE HERE
train_num = len(os.listdir(SOURCE_DIR)) * SPLIT_SIZE
train_list = random.sample(os.listdir(SOURCE_DIR), int(train_num))
for filename in os.listdir(SOURCE_DIR):
source = os.path.join(SOURCE_DIR, filename)
if os.path.getsize(source) == 0:
print(f'{filename} is zero length, so ignoring.')
continue
if filename in train_list:
copyfile(source, os.path.join(TRAINING_DIR, filename))
else:
copyfile(source, os.path.join(VALIDATION_DIR, filename))
### END CODE HERE
# Test your split_data function
# Define paths
CAT_SOURCE_DIR = "/tmp/PetImages/Cat/"
DOG_SOURCE_DIR = "/tmp/PetImages/Dog/"
TRAINING_DIR = "/tmp/cats-v-dogs/training/"
VALIDATION_DIR = "/tmp/cats-v-dogs/validation/"
TRAINING_CATS_DIR = os.path.join(TRAINING_DIR, "cats/")
VALIDATION_CATS_DIR = os.path.join(VALIDATION_DIR, "cats/")
TRAINING_DOGS_DIR = os.path.join(TRAINING_DIR, "dogs/")
VALIDATION_DOGS_DIR = os.path.join(VALIDATION_DIR, "dogs/")
# Empty directories in case you run this cell multiple times
if len(os.listdir(TRAINING_CATS_DIR)) > 0:
for file in os.scandir(TRAINING_CATS_DIR):
os.remove(file.path)
if len(os.listdir(TRAINING_DOGS_DIR)) > 0:
for file in os.scandir(TRAINING_DOGS_DIR):
os.remove(file.path)
if len(os.listdir(VALIDATION_CATS_DIR)) > 0:
for file in os.scandir(VALIDATION_CATS_DIR):
os.remove(file.path)
if len(os.listdir(VALIDATION_DOGS_DIR)) > 0:
for file in os.scandir(VALIDATION_DOGS_DIR):
os.remove(file.path)
# Define proportion of images used for training
split_size = .9
# Run the function
# NOTE: Messages about zero length images should be printed out
split_data(CAT_SOURCE_DIR, TRAINING_CATS_DIR, VALIDATION_CATS_DIR, split_size)
split_data(DOG_SOURCE_DIR, TRAINING_DOGS_DIR, VALIDATION_DOGS_DIR, split_size)
# Check that the number of images matches the expected output
# Your function should perform copies rather than moving images so original directories should contain unchanged images
print(f"\n\nOriginal cat's directory has {len(os.listdir(CAT_SOURCE_DIR))} images")
print(f"Original dog's directory has {len(os.listdir(DOG_SOURCE_DIR))} images\n")
# Training and validation splits
print(f"There are {len(os.listdir(TRAINING_CATS_DIR))} images of cats for training")
print(f"There are {len(os.listdir(TRAINING_DOGS_DIR))} images of dogs for training")
print(f"There are {len(os.listdir(VALIDATION_CATS_DIR))} images of cats for validation")
print(f"There are {len(os.listdir(VALIDATION_DOGS_DIR))} images of dogs for validation")
# GRADED FUNCTION: train_val_generators
def train_val_generators(TRAINING_DIR, VALIDATION_DIR):
"""
Creates the training and validation data generators
Args:
TRAINING_DIR (string): directory path containing the training images
VALIDATION_DIR (string): directory path containing the testing/validation images
Returns:
train_generator, validation_generator - tuple containing the generators
"""
### START CODE HERE
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
train_datagen = ImageDataGenerator(rescale=1./255)
# Pass in the appropiate arguments to the flow_from_directory method
train_generator = train_datagen.flow_from_directory(directory=TRAINING_DIR,
batch_size=100,
class_mode='binary',
target_size=(150, 150))
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
validation_datagen = ImageDataGenerator(rescale=1./255)
# Pass in the appropiate arguments to the flow_from_directory method
validation_generator = validation_datagen.flow_from_directory(directory=VALIDATION_DIR,
batch_size=100,
class_mode='binary',
target_size=(150, 150))
### END CODE HERE
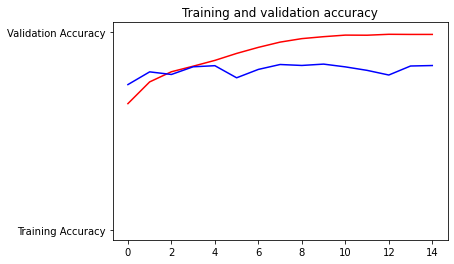
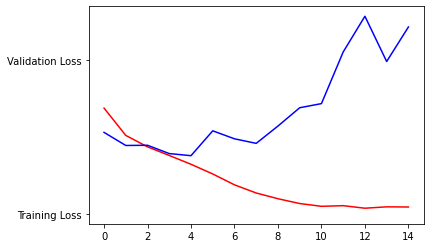
return train_generator, validation_generator- accuracy 가 충분히 올라가지 않 음
- batch_size 를 20에서 100으로 올림
# GRADED FUNCTION: create_model
def create_model():
# DEFINE A KERAS MODEL TO CLASSIFY CATS V DOGS
# USE AT LEAST 3 CONVOLUTION LAYERS
### START CODE HERE
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
### END CODE HERE
return model# Get the untrained model
model = create_model()
# Train the model
# Note that this may take some time.
history = model.fit(train_generator,
epochs=15,
verbose=1,
validation_data=validation_generator)
def download_history():
import pickle
from google.colab import files
with open('history.pkl', 'wb') as f:
pickle.dump(history.history, f)
files.download('history.pkl')
download_history()-> colab에서 history 를 pkl로 저장하기
2주차
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')- rotate_range : 0~180도 (0~40도 사이에 랜덤한 각도로 rotate)
- shift : 이미지 프레임 내에서 이미지 이동
...
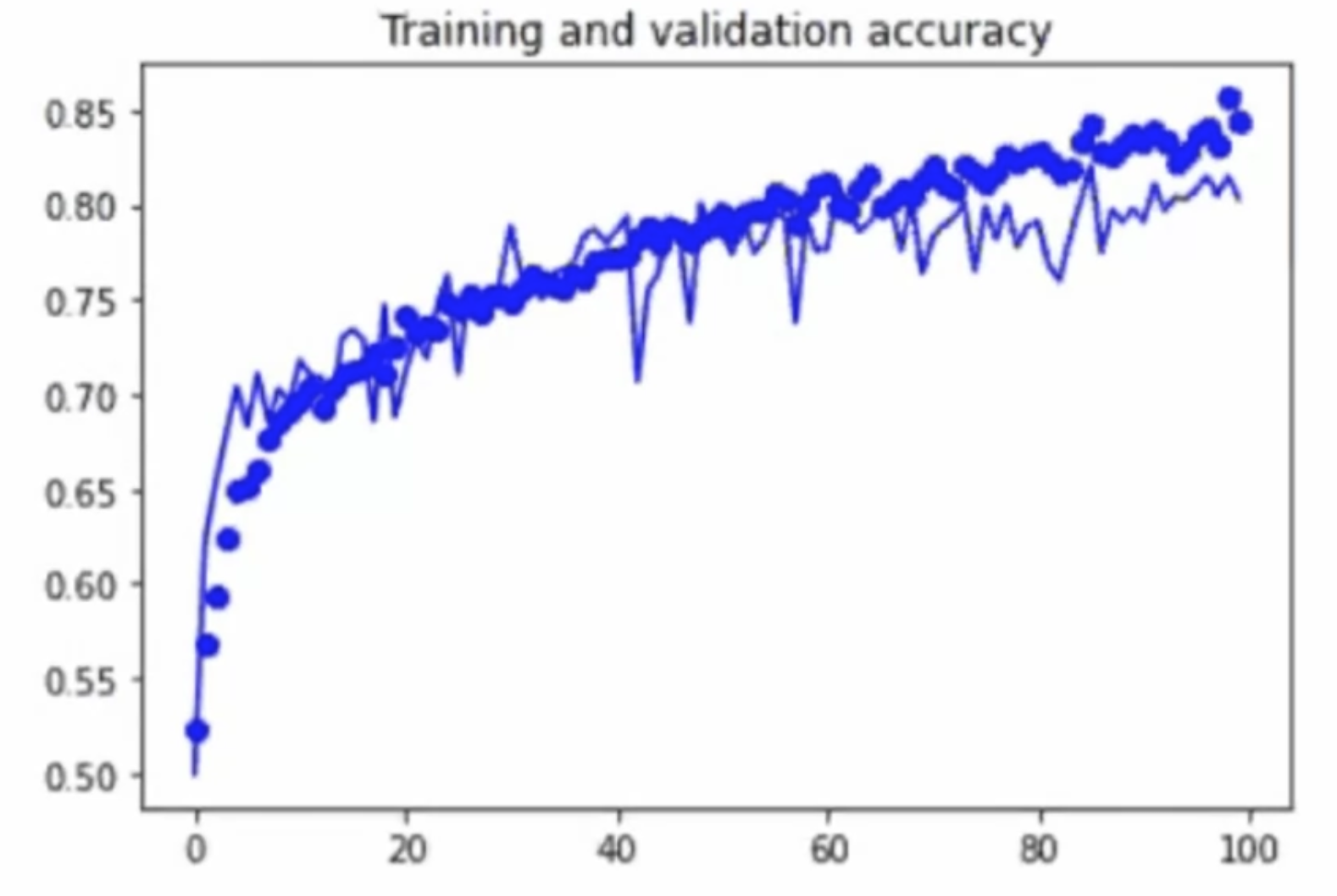
-> augmentation 적용했을 때
과제
다 똑같은데 ImageDataGenerator 부르는 부분만 다름
# GRADED FUNCTION: train_val_generators
def train_val_generators(TRAINING_DIR, VALIDATION_DIR):
"""
Creates the training and validation data generators
Args:
TRAINING_DIR (string): directory path containing the training images
VALIDATION_DIR (string): directory path containing the testing/validation images
Returns:
train_generator, validation_generator - tuple containing the generators
"""
### START CODE HERE
# Instantiate the ImageDataGenerator class (don't forget to set the arguments to augment the images)
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# Pass in the appropriate arguments to the flow_from_directory method
train_generator = train_datagen.flow_from_directory(directory=TRAINING_DIR,
batch_size=100,
class_mode='binary',
target_size=(150, 150))
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
validation_datagen = ImageDataGenerator(rescale=1./255)
# Pass in the appropriate arguments to the flow_from_directory method
validation_generator = validation_datagen.flow_from_directory(directory=VALIDATION_DIR,
batch_size=100,
class_mode='binary',
target_size=(150, 150))
### END CODE HERE
return train_generator, validation_generator3주차
import os
from tensorflow.keras import layers
from tensorflow.keras import Modelfrom tensorflow.keras.applications.inception_v3 import InceptionV3
local_weights_file = '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
pretrained_model = InceptionV3(
input_shape=(150,150,3),
include_top = False,
weights = None)
pretrained_model.load_weights(local_weights_file)- 마지막 fully connected layer 는 ignore
for layer in pretrained_model.layers:
layer.trainable = Falsefreeze(lock)
pretrained_model.summary()<엄청 긺>
마지막 레이어의 output 를 가져와서 나의 모델에 만들기
from tensorflow.keras.optimizers import RMSprop
last_layer = pretrained_model.get_layer('mixed7')
last_output = last_layer.output
x = layers.Flatten()(last_outputs)
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dense(1, activation='sigmoid')(x)
model = Model(pretrained_model.input, x)
model.compile(
optimizer=RMSprop(learning_rate=0.0001),
loss='binary_crossentropy',
metrics = ['acc'])
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)train_generator = train_datagetn.flow_from_directory(
train_dir,
batch_size=20,
class_mode = 'binary',
target_size = (150,150))history = model.fit(
train_generator,
validation_data = validation_generator,
steps_per_epoch = 100,
epochs = 100,
validation_steps = 50,
verbose =2)
이렇게 학습한 결과..
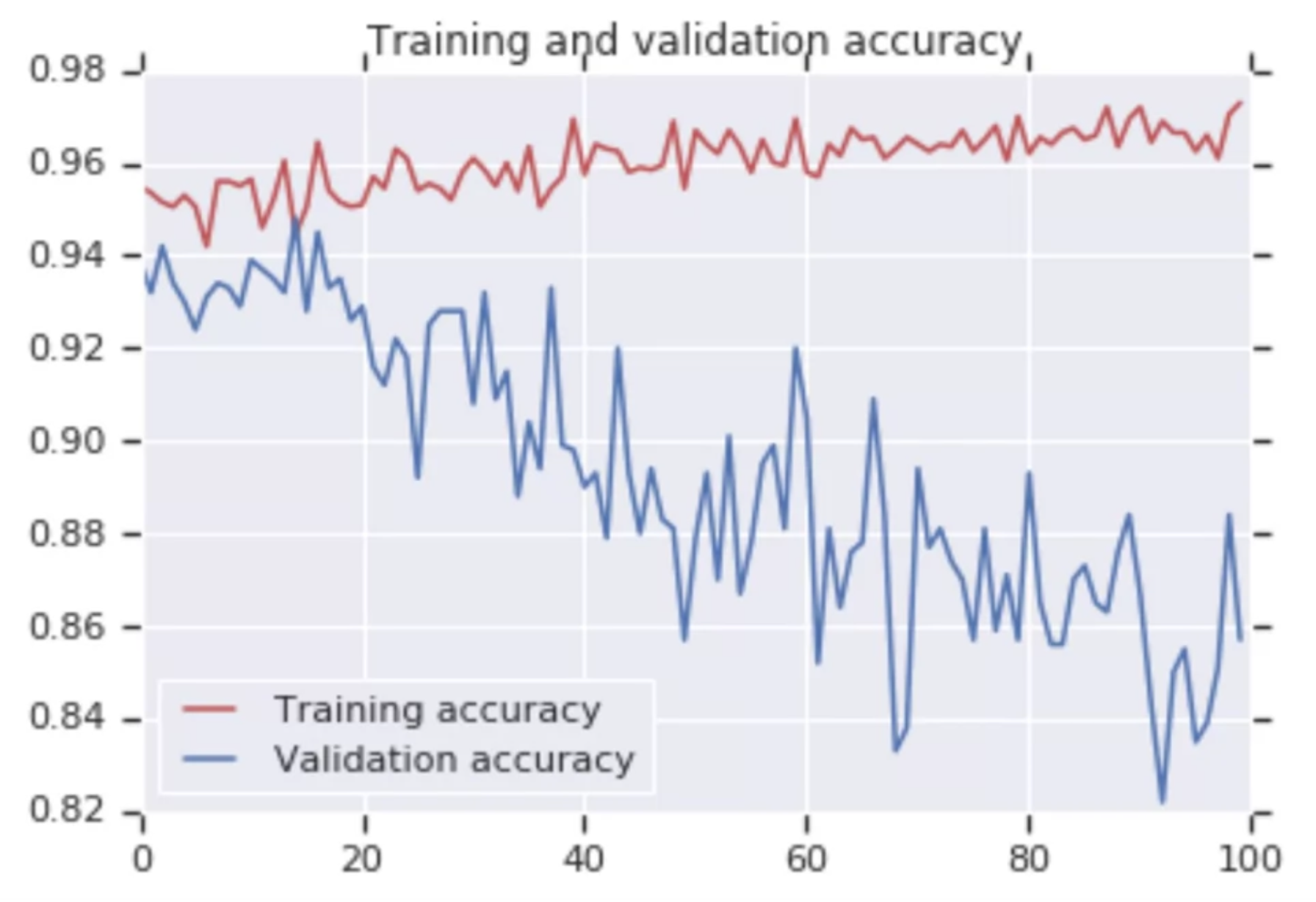
--> overfitting 방지하기 위한 Dropout!!!
from tensorflow.keras.optimizers import RMSprop
last_layer = pretrained_model.get_layer('mixed7')
last_output = last_layer.output
x = layers.Flatten()(last_outputs)
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dropout(0.2)(x) # dropout
x = layers.Dense(1, activation='sigmoid')(x)
model = Model(pretrained_model.input, x)
model.compile(
optimizer=RMSprop(learning_rate=0.0001),
loss='binary_crossentropy',
metrics = ['acc'])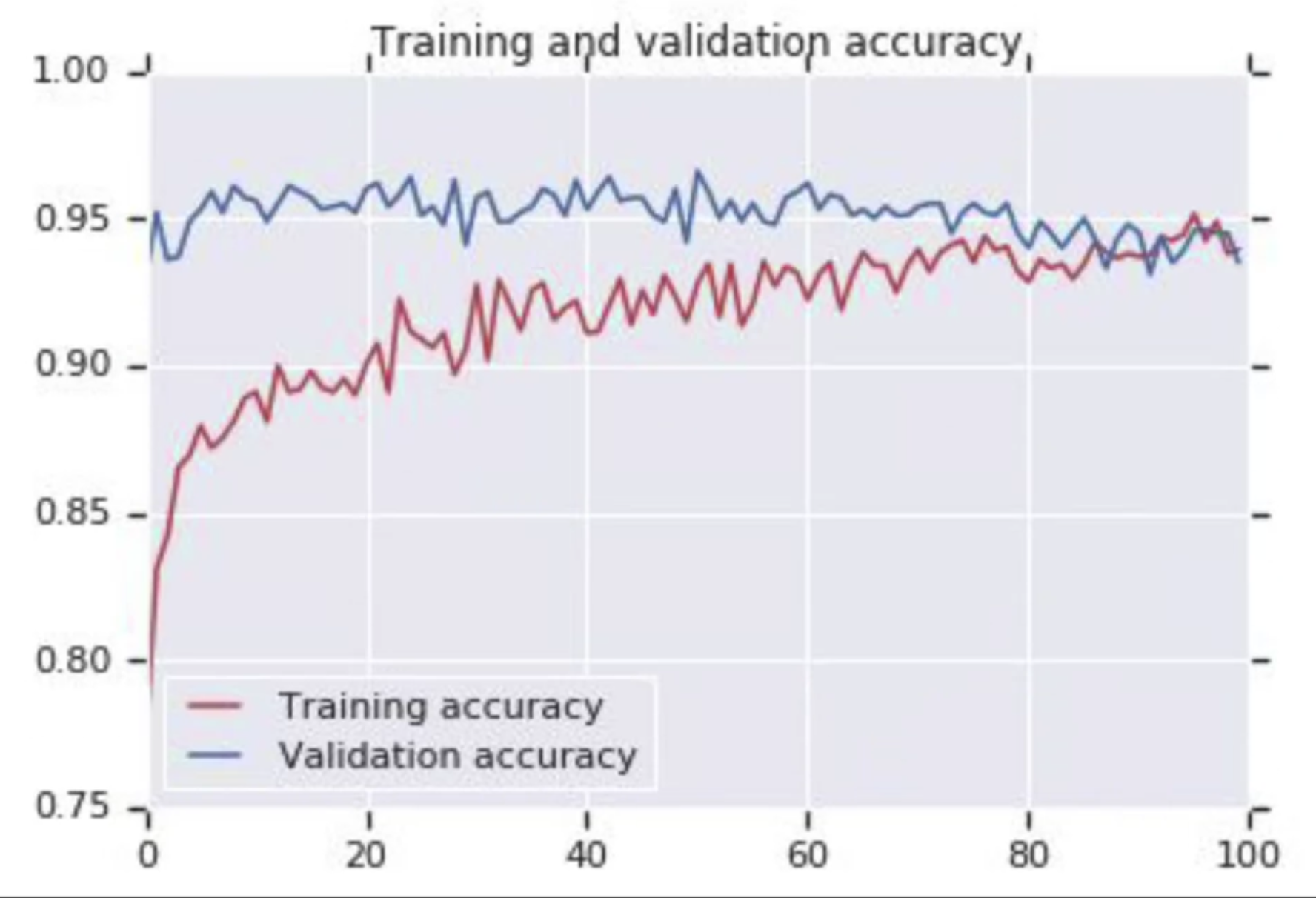
과제
위에 필기한 내용과 동일하게 진행합니다
4주차
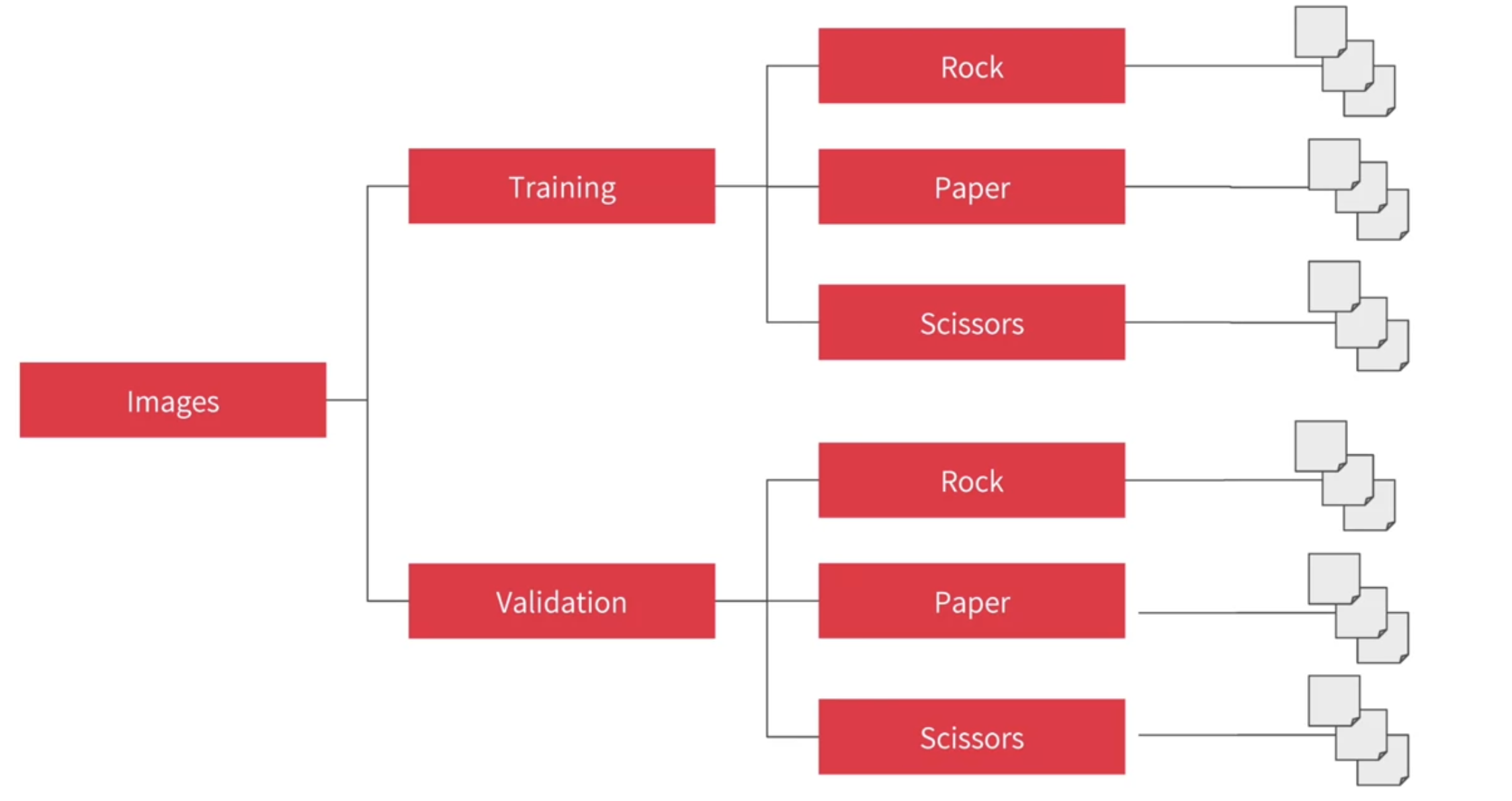
multi-class classfication 도 크게 다르지 않다
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size = (300,300),
batch_size = 128,
class_mode='categorical') # 이 부분 수정 model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax') # 이 부분 수정
])model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(lr=0.001),
metrics=['accuracy'])
가위바위보 workbook - 위에서 수정한 내용대로 진행함
과제
import csv
import string
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as pltcsv. 형태로 된 데이터 다운 받음
TRAINING_FILE = './sign_mnist_train.csv'
VALIDATION_FILE = './sign_mnist_test.csv'
# GRADED FUNCTION: parse_data_from_input
def parse_data_from_input(filename):
"""
Parses the images and labels from a CSV file
Args:
filename (string): path to the CSV file
Returns:
images, labels: tuple of numpy arrays containing the images and labels
"""
with open(filename) as file:
### START CODE HERE
labels = []
arrays = []
# Use csv.reader, passing in the appropriate delimiter
# Remember that csv.reader can be iterated and returns one line in each iteration
csv_reader = csv.reader(file, delimiter=',')
for num, row in enumerate(csv_reader):
if num==0:
continue
label = row[0]
pixel = np.reshape(row[1:], (28, 28))
labels.append(label)
arrays.append(pixel)
labels = np.stack(labels, axis=0).astype('float64')
images = np.stack(arrays, axis=0).astype('float64')
### END CODE HERE
return images, labels나도 이걸 우째 했는지 모르겠네 어쨌든 해냄
# Test your function
training_images, training_labels = parse_data_from_input(TRAINING_FILE)
validation_images, validation_labels = parse_data_from_input(VALIDATION_FILE)
print(f"Training images has shape: {training_images.shape} and dtype: {training_images.dtype}")
print(f"Training labels has shape: {training_labels.shape} and dtype: {training_labels.dtype}")
print(f"Validation images has shape: {validation_images.shape} and dtype: {validation_images.dtype}")
print(f"Validation labels has shape: {validation_labels.shape} and dtype: {validation_labels.dtype}")
# GRADED FUNCTION: train_val_generators
def train_val_generators(training_images, training_labels, validation_images, validation_labels):
"""
Creates the training and validation data generators
Args:
training_images (array): parsed images from the train CSV file
training_labels (array): parsed labels from the train CSV file
validation_images (array): parsed images from the test CSV file
validation_labels (array): parsed labels from the test CSV file
Returns:
train_generator, validation_generator - tuple containing the generators
"""
### START CODE HERE
# In this section you will have to add another dimension to the data
# So, for example, if your array is (10000, 28, 28)
# You will need to make it (10000, 28, 28, 1)
# Hint: np.expand_dims
training_images = np.expand_dims(training_images, axis=-1)
validation_images = np.expand_dims(validation_images, axis=-1)
# Instantiate the ImageDataGenerator class
# Don't forget to normalize pixel values
# and set arguments to augment the images (if desired)
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# Pass in the appropriate arguments to the flow method
train_generator = train_datagen.flow(x=training_images,
y=training_labels,
batch_size=32)
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
# Remember that validation data should not be augmented
validation_datagen = ImageDataGenerator(rescale=1./255)
# Pass in the appropriate arguments to the flow method
validation_generator = validation_datagen.flow(x=validation_images,
y=validation_labels,
batch_size=32)
### END CODE HERE
return train_generator, validation_generatorflow_from_directory 대신에 flow 를 쓴 점이 다름
# Test your generators
train_generator, validation_generator = train_val_generators(training_images, training_labels, validation_images, validation_labels)
print(f"Images of training generator have shape: {train_generator.x.shape}")
print(f"Labels of training generator have shape: {train_generator.y.shape}")
print(f"Images of validation generator have shape: {validation_generator.x.shape}")
print(f"Labels of validation generator have shape: {validation_generator.y.shape}")
def create_model():
### START CODE HERE
# Define the model
# Use no more than 2 Conv2D and 2 MaxPooling2D
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(26, activation='softmax')
])
model.compile(optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
### END CODE HERE
return model- loss 부분에 'sparse_categorical_crossentropy'
- Flatten()을 자꾸 까먹음
# Save your model
model = create_model()
# Train your model
history = model.fit(train_generator,
epochs=15,
validation_data=validation_generator)
'인공지능 > tensorflow certificate' 카테고리의 다른 글
| Sequences, Time Series, and Prediction(2) - Deep Learning (0) | 2022.08.22 |
|---|---|
| Sequences, Time Series, and Prediction(1) - mathematical method (0) | 2022.08.22 |
| Natural Language Processing in TensorFlow(2) (0) | 2022.08.21 |
| Natural Language Processing in TensorFlow(1) (0) | 2022.08.21 |
| Introduction to TensorFlow for Artificial Intelligence, ML, and DL (0) | 2022.08.18 |