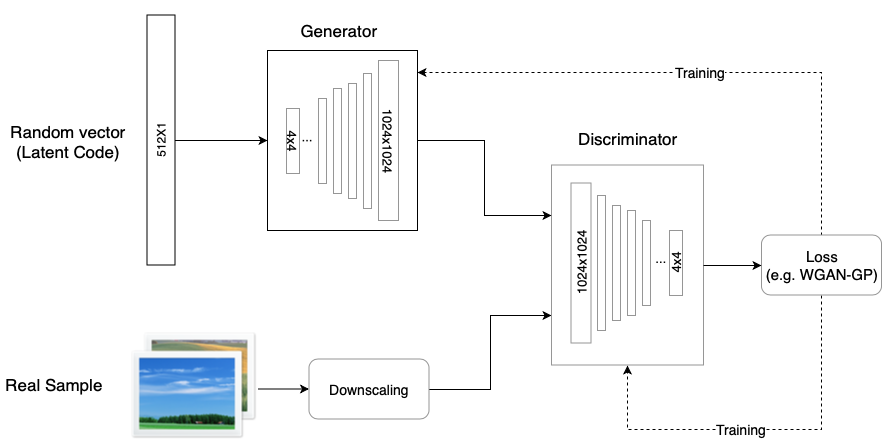
Progressive Growing of GANs for Improved Quality Stability and Variation(2017) - PGGAN
초록
새로운 GAN 학습 방법론. 핵심은 생성기와 식별기를 점진적으로 학습시키는 것이다. 낮은 해상도에서 시작해 새로운 레이어를 추가함으로써 학습 과정에서 점진적으로 디테일을 모델링한다. 학습의 속도가 빨라지고 상당한 안정성도 확보가 된다. 이로써 이전에는 불가능했던 퀄리티의 이미지를 생성할 수 있게 됐다. 또한 생성된 이미지들의 variation을 증가시킬 수 있는 단순한 방법도 제안한다. 비지도 CIFAR10에서 8.8점을 달성했다. 나아가 생성기와 식별기의 불건전한 경쟁(unhealthy competition)을 감소시키는 디테일을 적용하는 법도 제시했다. 마지막으로는 이미지 퀄리티와 variation 관점에서 GAN의 결과를 평가하는 새로운 평가 방법(metric)을 제안한다. 더 높은 퀄리티의 CELEBA 데이터셋을 구성했다.
Introduction
- 이미지 처리에서 두드러지는 접근법들의 장단점: autoregressive models, VAE, GAN
- GAN은 선명한 이미지를 생성할 수 있지만, 그래도 낮은 해상도에서만 가능하고 variation에 있어서도 한정적이다. 그리고 학습이 계속해서 불안정하다.
- GAN의 두 가지 네트워크: 생성기와 식별기
- 두 신경망 모두 미분가능하므로(differentiable), gradient를 구해 올바른 방향으로 신경망을 이끈다.
- 문제: 학습 데이터의 분포와 생성된 샘플 데이터의 분포 간 거리를 계산할 때 충분히 겹치는 부분(substantial overlap)이 없으면 gradient가 엉뚱한 방향으로 향할 수 있음. 결국에 (식별기 입장에서) 샘플들을 구분하는 게 너무 쉬워짐
- 기존에는 거리를 계산할 때 Jensen-Shannon divergence를 사용했는데, 이곳에서는 주로 개선된 Wasserstein loss를 사용함
- 두 신경망 모두 미분가능하므로(differentiable), gradient를 구해 올바른 방향으로 신경망을 이끈다.
- GAN으로 고해상도 이미지를 다룰 때의 문제
- 해상도가 좋을수록 식별기가 생성기의 가짜 샘플과 진짜 샘플을 구분하기 쉬위짐. 그 결과 gradient 문제가 증폭됨.
- 고해상도를 다룰 때에는 메모리 문제로 minibatch의 사이즈를 줄여야 함. 그 결과 학습이 불안정해짐.
→ 낮은 해상도에서 시작해 생성기와 식별기를 점진적으로 학습시킨 후, 학습 과정 중 고해상도 디테일을 도입하는 새로운 레이어를 추가함
- GAN에서는 생성 모델이 전체 학습 데이터의 분포를 나타낼 필요가 없다. 이미지 퀄리티와 variation 간 tradeoff 관계가 있다고 믿어져 왔지만, variation을 보존하는 등 다양한 방법론과 평가방식이 제시되고 있다.
보충
(1) PixelCNN : 이전의 픽셀값들을 통해 새로운 변수값, 즉 픽셀값을 예측하는 autoregressive 모델

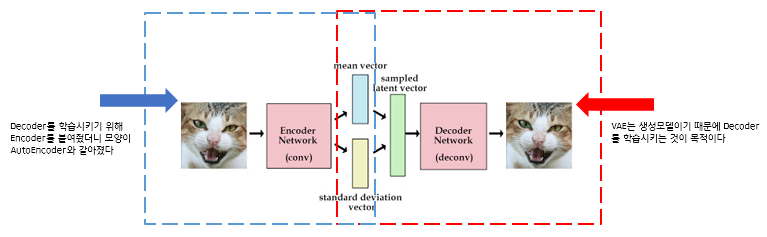
(2) variational autoencoders(VAEs): encoder는 관측된 x에서 잠재변수 latent vecter z를 만들어내고, decoder는 z를 활용해 x를 복원
(3) Jensen-Shannon divergence
두 확률 분포 모델을 비교하기 위해 KL-Divergence에 거리 개념을 도입한 식. 두 KL-Divergence 값의 평균.
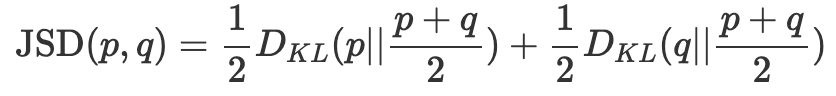
(4) Wasserstein
두 확률 분포가 겹치지 않을 때 (공집합이 없을 때) KL-Divergence는 무한대로 가고 Jensen-Shannon Divergence는 log2가 된다.
이는 두 확률 분포가 서로 다른 영역에서 측정된 경우 완전히 다르다고 판단하게끔 metric이 계산되기 때문이다. (= metric이 두 확률분포의 차이를 harsh하게 봄)
이는 GAN에서는 식별기의 학습이 죽는 원인이 된다. 이에 ‘수렴’에 포커스를 맞춘 metric을 도입하게 된다. 이 수렴은 TV, KL, JS보다 약한(weak) metric으로 soft한 성질을 가진다.

𝚼 : 두 확률분포의 결합확률분포들을 모은 집합 중에서 하나
모든 결합확률분포 Π(ℙ, ℚ) 중에서 d(X, Y)의 기대값을 가장 작게 추정한 값

(Ω에서 샘플링해온 ω를 통해) X(ω)와 Y(ω)를 뽑는다. 그 두 점 간의 거리 d(X(ω), Y(ω)) 를 계산할 수 있다. 샘플링을 거듭할수록 (X, Y)의 거듭확률분포 𝚼 의 윤곽이 나온다. 이때 𝚼 가 X, Y의 연관성(dependency)를 어떻게 측정하는지에 따라 d(X, Y)의 분포가 달라진다. Wasserstein distance는 여러가지 𝚼 중에서 d(X, Y)의 기대값이 가장 작게 나오는 확률분포를 취한다. *각 X와 Y의 분포는 변하지 않음
X~ℙ0, Y~ℙθ 일 때, ω에 대해서 X(ω) = (0, Z1(ω)), Y(ω) = (θ, Z2(ω)) 과 같이 매핑됨. X(ω)와 Y(ω) 사이의 거리는 다음과 같이 계산된다.

즉, d(X, Y)의 기대값은 어떤 𝚼를 사용하든 항상 |θ| 보다 크거나 같다.
|θ|와 같은 경우? 항상 Z1 = Z2 인 분포를 따를 때

Progressive growing
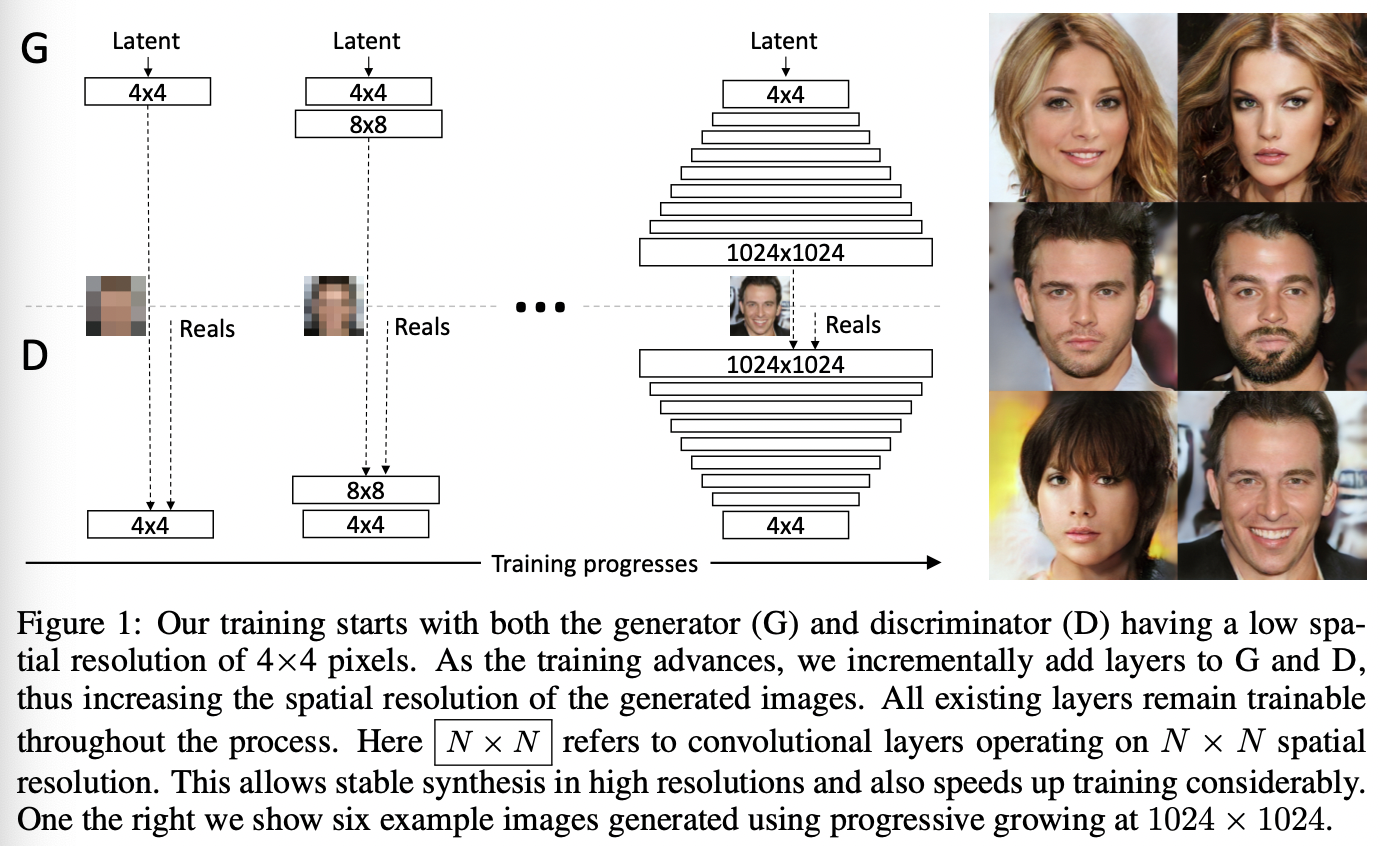
그림 1 : 생성기와 식별기 모두 해상도가 낮은 4*4 픽셀에서 훈련을 시작한다. 훈련이 진행될수록 점진적으로 두 신경망에 레이어를 추가해서 생성되는 이미지의 공간 해상도를 증가시킨다. 기존 레이어는 학습가능한 상태를 유지한다. N x N 은 N*N 공간 해상도로 작동하는 convolutional 레이어를 가리킨다. 이를 통해 고해상도에서 안정적인 합성이 가능하고 학습 속도도 빨라진다. 오른쪽 이미지는 1024*1024 로 점진적으로 늘려 생성한 예시다.
- 저해상도 이미지에서 시작해 레이어를 추가함으로써 점진적으로 해상도를 높인다.
- 큼직한 스케일에서 이미지 분포의 구조를 먼저 파악한 후 점진적으로 작은 스케일의 디테일로 옮겨감.
- 생성기와 식별기는 거울상을 이루며 항상 동시에 크기를 키운다
- 두 신경망 모두 기존 레이어들은 학습 가능한 상태를 유지함.
- fade them in smoothly: 먼저 훈련된 저해상도 레이어를 갑자기 놀래키는 것(sudden shocks)을 피함.
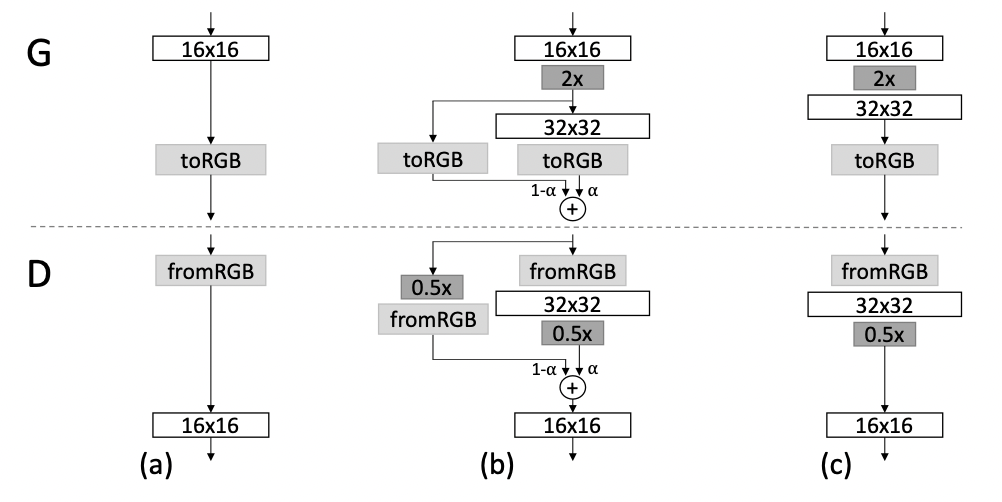
그림 2: 생성기와 식별기의 해상도를 두 배로 늘릴 때, 새로운 레이어를 smooth하게 추가한다. 위 예시에서는 16*16 이미지(a)에서 32*32 이미지(c)로 전환하는 과정을 보여준다. 전환 과정(b)에서 고해상도에서 작동하는 레이어들을 residual block처럼 다룬다. 레이어의 가중치 α가 0에서 1로 선형적으로 증가한다. nearest neighbor filtering으로 이미지를 2배 늘리고(2x) average pooling으로 이미지를 0.5배한다(0.5x). toRGB는 feature 벡터를 RGB 컬러에 사영(project)시키는 레이어이고 fromRGB는 그 반대이다. 두 레이어 모두 1*1 convolution을 사용한다. 식별기를 학습시키는 동안 현재 신경망의 해상도에 맞게 downscale된 실제 이미지를 투입한다. 해상도가 바뀌는 동안에는 진짜 이미지들의 해상도끼리 보간(interpolate)시킨다. 생성기의 출력이 두 해상도를 결합하는 방식과 유사함.


- 점진적인 학습의 장점
- 해상도를 조금씩 증가시킴으로써, 최종 목적(latent vector를 1024*1024 이미지로 매핑하기)에 비해 단순한 질문을 던지는 셈이 됨. 이것이 학습을 안정화시켜 megapixel-scale 이미지도 합성할 수 있음.
- 훈련 시간 단축. 대부분의 훈련이 저해상도에서 이루어지기 때문.
보충
- nearest neighbour filtering https://mkblog.co.kr/2018/12/04/texture_filtering_bilinear_trilinear_anisotropic/
Increasing variation using minibatch standard deviation
- GAN은 학습 데이터의 variation을 일부만 포착하는 경향이 있음.
- Salimans et al. (2016) : “minibatch discriminator”를 해결방안으로 제시함. 개별 이미지 뿐만 아니라 minibatch에 걸쳐서 feature 통계값을 계산, 생성 이미지와 학습 이미지가 비슷한 통계값을 갖도록 함.
- minibatch 레이어 : 입력 활성화값을 통계값에 사영(project), 즉 minibatch 속 각 샘플에 대한 통계값을 레이어의 출력값에 합쳐 식별기가 통계값을 내부적으로 사용할 수 있ㄷ로고 함
- minibatch discriminator 접근법을 적용하되 새로운 파라미터를 학습할 필요가 없는 단순한 방식을 소개한다.
- 1. minibatch에 걸쳐 각 공간 위치(픽셀 위치)의 각 feature에 대해 표준편차를 계산한다.
- 2. 모든 feature 및 공간 위치에 대한 이 추정값들을 단일 평균값으로 계산한다.
- 3. 그 값을 복제하여 모든 spatial location, 전체 minibatch에 걸쳐 concatenate한다. 그 결과로 새로운 (constant) feature map이 나온다.
- 이 레이어는 식별기 마지막 쪽에 삽입할 때 가장 좋은 값 나옴.
- variation 문제에 대한 또다른 해결방안으로 unrolling the discriminator 와 “repelling regularizer”
- unrolling the discriminator : 식별기의 업데이트를 정규화
- “repelling regularizer” : 새로운 손실항 추가
→ minibatch의 feature vector를 직교화(orthogonalize)하도록 한다
→ 논문의 접근법보다 이 방식이 variation을 더 증가시킬 수 있음을 인정함
Normalization in generator and discriminator
- 생성기와 식별기의 불건전한 경쟁의 결과로 signal magnitudes가 상승하기 쉽다.
- 이전에는 대부분 batch normalization으로 해결할 수 있었다. 이 방법론은 원래는 공변량 변화(covariance shift)를 막기 위해 도입되었지만, (공변량 변화는) GAN에서 이슈가 되지 않는 것으로 보인다.
- 따라서 GAN에 진짜로 필요한 것은 signal magnitude와 competition을 제한하는 것.
- 이를 위해 파라미터를 학습할 필요가 없는 색다른 접근법을 사용함.
- 균등 학습률(equalized learning rate)
- 섬세한 가중치 초기화(careful weight initialization) 대신에, 자명한 N(0, 1) 초기화를 사용해 런타임 동안에 weight를 조절한다.
- ŵ = w/c (c : He’s initializer의 레이어당 규격화 상수(per-layer nolmalization constant))
- 균등 학습률의 장점 : RMSProp이나 Adam 같은 adaptive 확률적 경사하강법에서 흔히 사용되는 척도불변성(scale-invariance)와 관련될 수 있음. 이 방법은 추정된 표준편차를 통해 gradient 업데이트를 정규화함으로써 파라미터의 규모와 독립적으로 업데이트가 이루어질 수 있도록 한다. 그 결과 어떤 파라미터들이 더 큰 동적 범위(dynamic range)를 가질 때 조정하는 데 더 오래 걸리게 됨. 오늘날 초기화 기법에서 발생하는 현상으로, 학습률이 너무 큰 동시에 너무 작은 상황이 가능하게 됨. 우리의 접근법은 동적 범위(dynamic range), 즉 학습률이 모든 가중치에 대해 동일하도록 함.
- 생성기의 픽셀 단위 벡터 정규화(pixelwise feature vector normalization in generator)
- 경쟁 끝에 생성기와 식별기의 크기(magnitudes)가 통제에서 벗어나게 되는 상황을 방지하기 위해, 생성기에서 각 convolutional layer 다음 각 픽셀의 feature vector를 단위 길이(unit length)로 정규화한다.
- 이를 위해 “local response normalization” 변수를 사용한다.
- 균등 학습률(equalized learning rate)
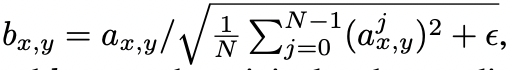
-
- ε = 10−8
- N : feature map의 개수
- ax,y : 기존 픽셀 (x, y)의 feature 벡터
- bx,y : 정규화된 픽셀 (x, y)의 feature 벡터
- 이렇게 강합적인 제한 방식으로도 생성기를 해치지 않으면서 signal magnitude의 상승을 매우 효과적으로 방지할 수 있음.
보충
- smooth fading in
처음에 16*16 해상도로 RGB 이미지를 생성시켰으면 그 다음으로 32*32 해상도를 학습시킨다. 하지만 학습되지 않은 32*32 레이어가 갑자기 끼어들면 잘 학습된 저해상도 레이어도 영향을 받을 수 있음. 스무스하게 레이어를 출력하기 위해 이전에 학습시킨 레이어의 출력 결과물을 활용한다.
16*16 이미지를 32*32 스케일로 늘리고, 32*32 레이어에서 만든 이미지와 결합한다. 후자의 각 픽셀값에 알파(0~1 사이 비율값)를 곱하고, 저해상도 픽셀에는 (1-알파)를 곱해서 서로 더한다. 이때 알파는 점차 1을 향해 증가시켜 이전 레이어의 영향력을 줄어들게 한다. 이로써 기존 저해상도의 학습된 방향을 망가뜨리지 않고 새로 추가된 레이어를 학습시킬 수 있다
- He’s initializer
- 벡터의 정규화
벡터의 길이를 단위 길이가 되게 해서 단위 벡터로 만드는 것을 가리켜 벡터의 정규화(normalization)라고 부른다. 벡터의 각 성분을 벡터의 크기로 나누면 벡터가 정규화 된다
- covariate shift
'인공지능 > computer vision' 카테고리의 다른 글
| styleGAN 이해하기 (0) | 2022.05.31 |
|---|---|
| PGGAN의 공식 코드 살펴보기 (0) | 2022.05.31 |
| DCGAN 이해하기 (0) | 2022.05.16 |
| GAN 이해하기 (0) | 2022.05.15 |
| distinctive image features from scale-invariant keypoints (0) | 2022.05.11 |