
A Style-Based Generator Architecture for Generative Adversarial Networks(2018)
<GAN을 위한 스타일 기반 생성기 아키텍처>
1. 초록
style transfer 개념을 빌려 새로운 GAN 생성기 아키텍처를 제안. 새로운 학습기는 고차원적인 특징(자세, 인종identity)과 생성 이미지의 확률적 다양성(stochastic variation, 주근깨나 헤어스타일)을 개별적으로 비지도 자동학습하며, 합성에 있어서 직관적이고 scale-specific한 통제를 가능케 한다. 새로운 생성기는 기존 분포특성 평가방식(traditional distribution quality metrics)에 있어서 최신 기술을 개선하고 더 나은 보간식(interpolation properties)을 제시한다. 또한 variation의 잠재 요소들을 더 잘 분리(disentangle)한다. interpolation quality 와 disentanglement를 양적으로 나타내기 위해 어느 생성기 아키텍처에나 적용할 수 있는 두 가지 자동화 방식을 제시한다. 마지막으로 매우 다양하고 질적으로 좋은 새로운 인간 얼굴 데이터셋을 공개한다.
- “high-level attributes”: 자세나 인종 같은 것은 근본적이고 고차원적인 특징. 해상도가 낮아도 알아차릴 수 있을 정도로 근본적인 부분!
- “stochastic variation”: 반면 주근깨나 헤어스타일 같은 것은 이미지 속에서 확률에 따라 다양하게 나타날 수 있는 디테일한 특징. 해상도가 높을 때 확인하기 쉽다.
2. Style Transfer 개념

- 이미지 P가 이미지 A의 스타일을 갖도록 새로운 이미지를 생성하는 것
2.1. Neural style transfer의 시작
Image Style Transfer Using Convolutional Neural Networks (Gatys et al.)
- content image의 content와 style image의 style을 가지는 새로운 이미지 생성
- pre-trained CNN의 feature를 사용하는 알고리즘
- pre-trained CNN으로 VGG19 네트워크 사용
- 추가로 (1) 가중치 정규화, (2) max pooling 대신 average pooling 사용
- CNN 레이어에서 feature 추출
- content : 레이어가 깊어질수록 픽셀 수준의 정보는 사라지지만 semantic한 정보가 유지되므로 깊은 레이어에서 추출
- style : 각 레이어의 feature map 사이의 상관관계를 나타내는 Gram matrix를 사용
- Gram matrix: feature space 상 통계값(statistics)을 추출하는 방법
- loss 정의
-
- 생성될 이미지 x를 noise를 통해 임의로 생성
- content loss : content 이미지의 feature map과 생성될 이미지의 feature map 가지고 계산
- style loss : style 이미지의 gram matrix와 생성될 이미지의 gram matrix 가지고 계산
- content loss 와 style loss 각각에 어느 정도 가중치를 둬서 (무엇을 더 중점적으로 할 것인지에 따라) 결합한 것이 total loss
- 이때, total loss를 통해 업데이트 되는 것은 네트워크가 아니라 생성될 이미지이다.
2.2. Style Transfer in Real-Time With Adaptive Instance Normalization (AdaIN)
- 여기서 인코더가 아닌 디코더만 업데이트 : AdaIN으로 생성된 feature들이 디코더를 통해 image space로 invert하도록 학습
3. Introduction
- 잠재 공간에 대한 이해 부족
- style transfer 개념(AdaIN)에 영감을 받아 새로운 방식으로 이미지 합성 과정을 통제할 수 있도록 생성기 아키텍처를 디자인
- 생성기는 학습된 constant input에서 시작해, 잠재 코드를 기반으로 각 conv 레이어의 이미지 스타일을 조정한다. 네트워크로 바로 주입되는 noise와 함께, 아키텍처는 확률적 variation에서 고차원 특성을 비지도 자동 방식으로 분리할 수 있게 된다. 또한 직관적인 scale-specific mixing과 보간 연산도 가능하다. 식별기나 손실 함수는 수정하지 않음.
- 생성기는 입력 잠재 코드(input latent code)를 중간 잠재 공간(intermediate latent space)에 끼워넣음
- variation의 요소들이 신경망에 표현(represented)되는 방식에 근본적인 효과를 줌
- 입력 잠재 공간(input latent space)은 학습 데이터의 확률 밀도를 따라야 하기 때문에 이것이 불가피하게 entanglement(얽힘)으로 이어진다고 주장
- intermediate latent space은 그러한 제약(확률 밀도를 따라야 한다는 것?)으로부터 자유롭고 따라서 disentangled(풀림)될 수 있다
- (잠재 공간의 disentanglement 정도를 추정하기 위한) 새로운 두 가지 automated metrics 제안
- perceptual path length
- linear separability
- “선형 구분 가능(linearly separable)은 다차원 공간에 분포한 두 집단이 하나의 다차원 평면(hyper plane)으로 구분 가능함을 의미한다.” - 위키
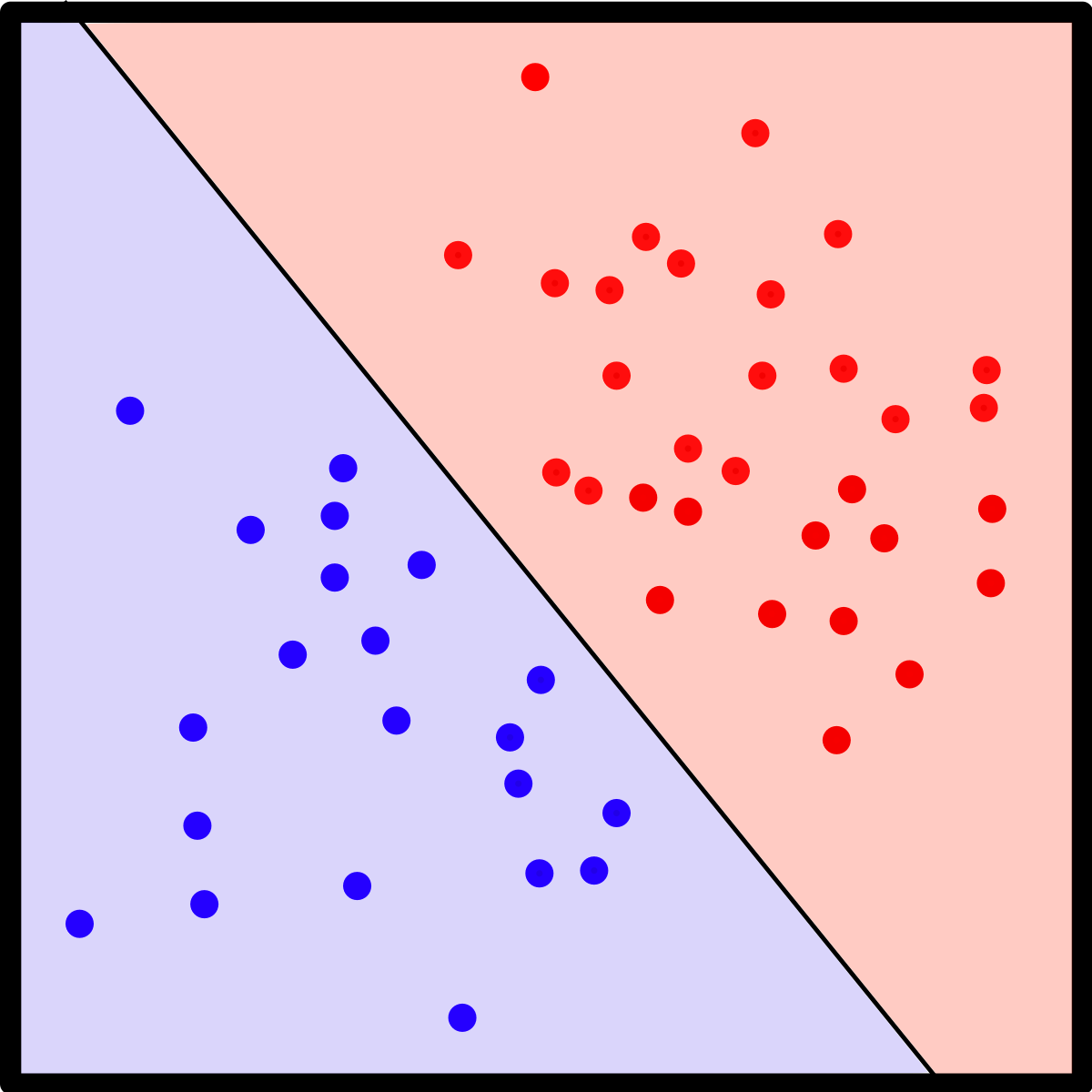
→ our generator admits a more linear, less entangled representation of different factors of variation
4. Style-based generator
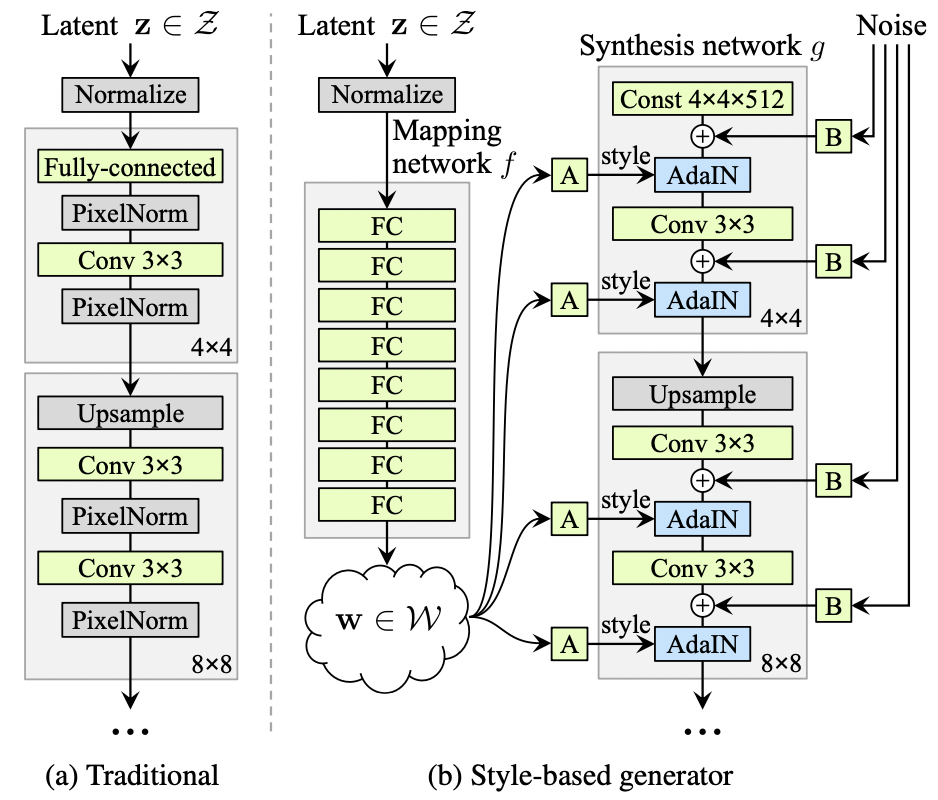
[그림 1] 기존 생성기는 입력 레이어에만 잠재 코드를 먹이는 반면, 우리는 입력을 중간 잠재 공간 W으로 맵핑한다. 다음 각 conv 레이어에서 adaptive instance normalization(AdaIN)를 통해 생성기를 통제한다. 가우시안 노이즈는 비선형성(nonlinearity)을 평가하기 전 각 conv 레이어 다음에 추가된다. A는 학습된 affine 변환을 가리키며, B는 학습된 채널별 scaling factor를 입력 노이즈에 적용한다. 맵핑 신경망 f 는 8개 레이어로 이뤄져 있으며, 합성 신경망 g는 18개 레이어로 이뤄져 있다. (해상도 별로 두 개) 마지막 레이어의 출력은 1*1 conv를 사용해 RGB로 변환된다. 이곳 생성기는 총 2620만 개 학습 파라미터가 있음. (기존 생성기는 2310개)
- 편의를 위해 입력 잠재공간 Z와 중간 잠재공간 W를 모두 512차원으로 설정, 맵핑함수 f는 8개 다중신경망 레이어로 적용
- 학습된 affine 변환이 w를 스타일 y로 특화시켜(specialize), 합성 신경망 g의 각 conv 레이어 다음에 오는 AdaIN 연산을 통제한다
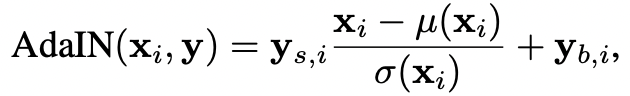
-
- 각 피처맵 xi은 각각 정규화되며, 스케일링을 거쳐, 이에 대응되는 style y의 스칼라 성분(scalar components)을 이용해 bias를 적용한다. 따라서 y의 차원은 해당 레이어의 feature map 개수의 두배이다. (?????)
- explicit noise inputs를 도입함으로써, 생성기에 직접 평균값을 주었을 때 확률적인 디테일을 생성할 수 있도록 했다. 이들은 비상관적인(uncorrelated) 가우시안 노이즈로 이루어진 단일채널(single-channel) 이미지들로, 합성 신경망의 각 레이어에 맞춰(dedicated) 노이즈를 먹인다. 노이즈 이미지는 학습된 feature별 scaling factor를 통해 모든 피처맵으로 브로드캐스팅되고, 이에 대응되는 conv 레이어의 출력값에 더해진다.
4.1. quality of generated images
- 아키텍처를 재구성함으로써 이미지의 퀄리티를 개선했음
- (B) bilinear up/downsampling, longer training, tuned hyperparameters
- (C) mapping network, AdaIN operations
- (D) removed the traditional input layer, started from a learned 4 * 4 * 512 constant tensor
- (E) noise inputs
- (F) mixing regularization : 이웃하는 스타일 간 상관관계를 줄이기
5. Properties of the style-based generator
- 스타일에 스케일별로(scale-specific) 수정을 가해 이미지를 합성하는 것이 가능
- 맵핑 신경망, 아핀 변환 : 학습된 분포의 각 스타일에서 샘플을 추출
- 합성 신경망 : 스타일 콜렉션을 기반으로 새로운 이미지를 생성
- 각 스타일의 효과들(effects)은 신경망에 localized되어 있음
- 스타일들의 특정 부분집합을 수정하면 이미지의 특정 부분만 영향 받을 것
- localization의 이유?
- AdaIN 연산이 처음에 각 채널을 평균 0, 단위 분산(1)으로 정규화, 그 후에 scales와 스타일 기반 biases를 적용
- 스타일에 따른(dictated) 채널별 통계값은 이어지는 conv 연산에 대해 상대적인 feature 중요도를 수정
- 정규화로 인해 기존 통계값에 의존하지 않음
→ 각 스타일은 다음 AdaIN 연산에 의해 재정의(overriden)되기 전에 오직 하나의 convolution만 통제함
5.1. style mixing
- 스타일의 지역화(localize)를 더욱 촉진하기 위해 mixing regularization을 도입함으로써 학습 과정에서 하나가 아닌 두 개의 임의 잠재 코드를 사용해 특정 확률의 이미지들(a given percentage of images)을 생성
- 이미지를 생성할 때 합성 신경망의 임의의 지점에서 잠재 코드를 나머지 하나로 바꿔치기 (style mixing)
- 매핑 신경망에 두 개의 잠재 코드 z1, z2를 통과시켜 이에 대응하는 w1, w2로 스타일을 통제
- 교차점(crossover point) 이전에 w1를 적용하고 교차점 이후에 w2를 적용함
- 이러한 정규화 기술은 신경망이 인접한 스타일끼리 상관관계가 있다고 추정하지 않도록 함

[그림 3] A와 B에서 각각 생성된 이미지 쌍. 그 가운데는 B로부터 명시된 부분집합 스타일을 가져오고 나머지는 A로부터 가져와 생성된 이미지. 거친 공간 해상도(coarse spatial resolutions, 42 - 82)에 대응하는 스타일을 복사해왔을 때 자세, 전체적인 헤어스타일, 얼굴형, 안경 같은 고차원 요소를 B로부터 가져옴. 색깔(눈, 머리, 조명)과 디테일한(finer) 얼굴 특징은 A를 닮음. B에서 중간 해상도 스타일을 복사해 오면 얼굴 특징, 헤어스타일, 눈뜸/감음 같이 좀더 작은 스케일 정보(smaller scale)를 B에서 받아옴. 자세, 얼굴형, 안경 같은 것은 A의 정보가 보존됨. 마지막으로 세세한 스타일(fine styles, 642 - 10242)을 B에서 받아오면 배색과 미세구조와 같은 부분을 주로 받아옴.
5.2. stochastic variation

[그림 4] stochastic variation의 예. (a) 두 개의 생성 이미지 (b) 입력 노이즈의 서로 다른 실현들(different realizations)을 확대한 것. 전체적인 모습은 거의 동일하지만 머리카락 각각은 매우 다르게 배치된다. (c) 100개 다른 실현들의 각 픽셀의 표준편차, 하이라이트된 부분들은 이미지가 노이즈에 따라 영향받는 부분이다. 주로 머리카락, 실루엣, 배경. eye reflection의 stochastic variation이 흥미로움. 인종이나 자세 같은 전역적인 측면은 stochastic variation에 영향받지 않는다.사람의 형상에서 stochastic하다고 볼 수 있는 부분이 많은데, 정확한 머리카락 배치라든가, 수염, 주근깨, 모공 같은 것들이 있다. 올바른 분포를 따르는 한 이러한 요소들은 이미지에 대한 인식(perception)에 영향을 미치지 않고 randomized 될 수 있다.

[그림 5] 생성기의 레이어에 따른 노이즈 input의 효과. (a) 모든 레이어에 노이즈를 적용. (b) 노이즈 없음 (c) 촘촘한 레이어(fine layers, 642 - 10242)에만 노이즈를 적용. (d) 거친 레이어(coarse layers, 42 -322)에만 노이즈를 적용. 노이즈를 인위적으로 생략했을 때 feature가 없는 “그림 같은(painterly)” 모습이 나옴. 거친 노이즈(coarse noise)는 큼직한(large-scale) 곱슬 머리와 배경 특징으로 이어지고, 촘촘한 노이즈(fine noise)는 더 촘촘한 곱슬머리와 디테일한 배경, 모공을 보여준다.
- 기존 생성기가 stochastic variation을 적용하던 방식
- 하나뿐인 입력이 input layer를 통과한다고 했을 때, 신경망은 필요할 때마다 이전 활성화값에서 ‘공간에 따라 변하는 유사난수(spatially-varying pseudorandom numbers)’를 생성할 줄 알아야 함
- 신경망의 capacity를 소비하고, 생성된 신호의 주기성을 숨기기 어려움. 항상 성공적이지도 않음. (생성된 이미지에서 흔히 보이는 패턴 통해 입증)
→ conv 마다 픽셀별 노이즈를 추가함으로써 이러한 이슈를 피한다
- [그림 4] : 노이즈는 stochastic한 부분들만 영향을 미치고 전체적인 구성이나 인종 같이 고차원인 부분은 건드리지 않음
- [그림 5] : 레이어의 다양한 부분집합에 stochastic variation을 적용했을 때의 효과. *동영상을 참고하라고 함
- 노이즈의 효과가 신경망에서 tightly localized 되어 있음
- 가정 : 생성기에서 어느 순간이든 가능하면 새로운 내용(content)를 가져와야 한다는 압박이 있고, stochastic variation을 생성하는 가장 쉬운 방법은 제공된 노이즈에 의존하는 것이다.
- 새로운 집합의 노이즈를 레이어마다 사용할 수 있으므로 이전 활성화값으로부터 stochastic effects를 가져올 필요가 없음 → localized effect
5.3. seperation of global effects from stochasticity
- 앞서 논의한 내용과 궤를 같이하는 style transfer literature: 공간 불변 통계값(spatially invariant statistics)이 이미지의 스타일을 인코딩하고, 공간에 따라 변화하는(spatially varying) features가 구체적인 경우(specific instance)를 인코딩한다.
- 우리의 생성기는 전체 피처맵이 같은 값을 가지고 스케일링되고 bias가 적용되었기 때문에 스타일이 이미지 전체에 영향을 미친다. 따라서, 자세, 조명, 배경 스타일 같은 전역적인 효과(global effect)는 일관적으로(coherently) 통제될 수 있다.
- 한편, 노이즈는 독립적으로 각 픽셀에 추가되므로 stochastic variation을 통제하기에 이상적으로 알맞다.
- 만약에 신경망이 노이즈를 활용해 자세를 통제하려고 한다면, 이는 공간적으로 비일관적인 결정(spatially inconsistent decisions)으로 이어질 것이며 식별기에 의해 penalized될 것이다(????)
- 그러므로 신경망은 명시적인 유도(explicit guidance) 없이 전역적, 지역적 채널을 적절하게 사용하도록 학습한다.
6. disentanglement studies
- disentanglement
- 선형적인 부분 공간으로 이루어진 잠재 공간. 각 부분 공간은 variation의 한 요소를 통제한다.
- Z의 요소들의 각 결합에 대한 표본추출확률(sampling probability)은 그에 대응하는 학습데이터의 밀도와 맞아야 한다. 이 때문에 요소들이 보통 데이터셋과 입력 잠재 분포와 완전히 분리(fully disentangled)될 수가 없음
- 우리 생성기의 주요 장점
- 중간 잠재 공간 W : 고정된 분포의 표본추출(sampling according to any fixed distribution)을 support할 필요가 없다
- 학습된 구분연속함수(piecewise continuous mapping) f(z)로부터 표본추출밀도(sampling density)가 유도된다
- 구분연속함수: 둘 이상의 구간으로 나뉘고, 각 구간에서 연속인 함수
- 이 매핑은 W를 “unwarp”하기 위해 조절되며, 이를 통해 variation의 요소들이 더 선형적이게 된다.
- 생성기가 그렇게 하도록 하는 압박이 있을 거라고 상정; entangled representation보다 disentangled representation을 기반으로 할 때 사실적인 이미지를 생성하는 것이 더 쉽기 때문
- 비지도 학습 환경(variation의 요소들을 미리 알 수 없는)에서 학습을 통해 덜 entangled된 W가 나오기를 기대
- disentanglement를 정량화하는 최근 metric들은 입력 이미지를 잠재 코드로 매핑해주는 인코더 신경망을 필요로 함 → 이곳 베이스인 GAN은 인코더가 없다
- 인코더도 필요 없고 variation의 요소에 대한 정보도 필요없는 두 가지 disentanglement 정량화 방식을 제안
6.1. perceptual path length
- 잠재 공간의 벡터를 보간(interpolation)하는 것은 이미지에서 비선형적인 변화를 불러옴
- 양 끝점에서 보이지 않던 특징feature들이 선형적인 보간 경로의 중간에 나타날 수 있음
→ 잠재 공간이 entangled되어 있으며 variation의 요소들이 제대로 분리되어 있지 않다는 의미
- 잠재 공간에서 interpolation하는 동안 사진에서 얼마나 극적인 변화가 나타나는지 측정
- 직관적으로 생각했을 때, 매우 휜(highly curved) 잠재공간보다 덜 휜(less curved) 잠재공간에서 더 부드러운 전환(smoother transition)이 일어날 것임
- perceptually-based pairwise image distance(지각 기반 이미지쌍 거리) 를 metric의 기본으로 사용
- 두 VGG16 임베딩 사이의 weighted difference를 계산
- where weights are fit : 인간 지각 유사성 판단(human perceptual similarity judgments)에 metrics가 agree하도록 ..
- 참고 [논문리뷰] The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
- 잠재 공간의 보간 경로를 선형적인 부분(linear segments)들로 나눈다면, 부분 경로의 전체 perceptual length를 정의할 수 있음 - 이미지 거리 metric으로 나타내는, 각 부분들에 대한 perceptual difference의 총합
- perceptual path length의 정의 : 우리는 총합의 극한값 대신에 small subdivision(ε) 을 이용해 근사치를 구한다
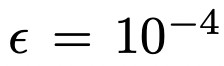
모든 끝점에 대한, 잠재 공간 Z의 평균 perceptual path length는
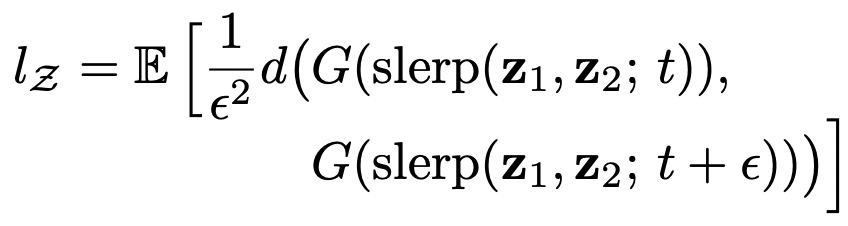
- z1, z2 ~ P(z)
- t ~ U(0, 1)
- G : 생성기
- metric d( , ) : 생성된 이미지들 사이 perceptual distance를 계산 → 2차이기 때문에 ε2로 나눔
- slerp : 구면 선형 보간
- 100,000 샘플로 기대값 계산
- 배경이 아니라 얼굴 feature에 집중하기 위해, 이미지쌍 metric을 측정하기 전에 얼굴만 보이도록 생성 이미지를 크롭
중간 잠재 공간 W의 평균 perceptual path length
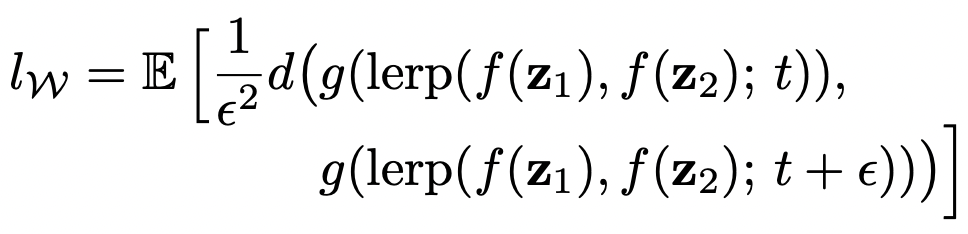
- 보간이 W 공간에서 이루어진다는 점만 다름
- W의 벡터는 정규화되지 않으므로 선형 보간(lerp)
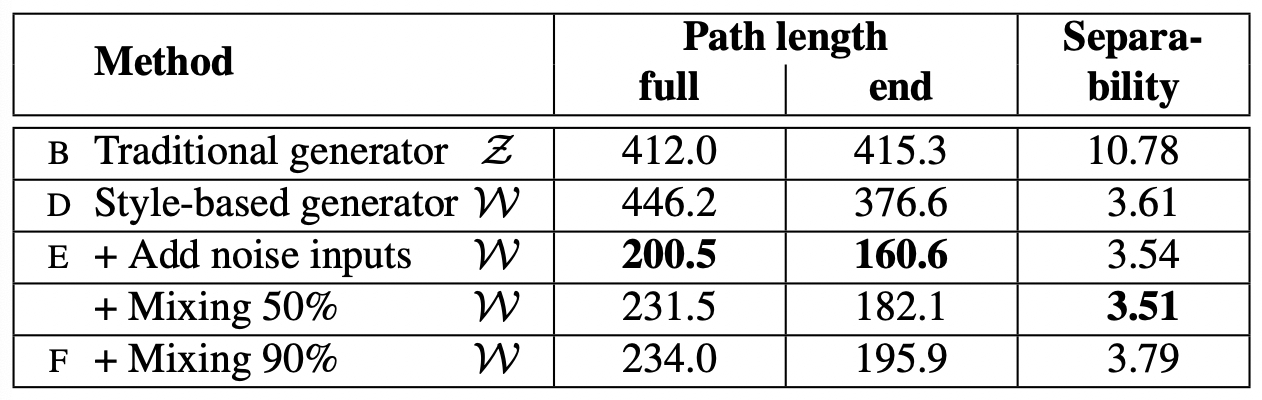
-
noise inputs를 추가한 style-based 생성기에서 전체 경로 길이(full-path length)가 충분히 짧다
- Z보다 W가 지각적으로 더 선형적이다
- 하지만 이 값도 input latent space Z 쪽으로 살짝 biased 되어 있음
- 만약 W이 정말로 disentangled하고 “flattened”한 매핑이라면, it may contain regions that are not on the input manifold and are thus badly reconstructed by the generator, even between points that are mapped from the input manifold, whereas the input latent space Z has no such regions by definition.
- 따라서 끝점들 간 경로를 잇는 기준(measure)을 제한한다면 (t ∈ {0, 1}), lz가 영향을 받지 않으면서 더 작은 lw를 얻을 수 있을 것.
- 매핑 신경망에 따라 path length 가 영향 받는 방식
- 기존 생성기, style-based 생성기 모두 mapping 신경망이 있을 때 benefit
- 깊이를 더 깊게 하면 perceptual path length가 개선됨
- 기존 생성기에서 lw는 좋아지는데, lz은 상당히 안 좋아짐 : input latent space가 GAN에서 임의적으로 entangled될 수 있다
6.2. Linear separability 선형 분리 가능
- latent space가 충분히 disentangled되어 있으면, variation의 개별 요소들에 일관적으로 상응하는 방향 벡터를 찾을 수 있다
- 잠재 공간의 점들을 선형적인 hyperplane 상 두 개의 별개 집합으로 얼마나 잘 나눌 수 있는지 측정함으로써 정량화하는 metric
- 각 집합이 이미지의 특정 binary attribute에 상응하게 됨
- 생성 이미지를 라벨링하기 위해, 여러 binary attribute에 대해 보조 분류신경망을 학습 (ex. 남자 얼굴 - 여자 얼굴) : 식별기와 동일한 아키텍처로 구성
- 한 attribute의 분리가능성을 측정하기 위해 z ~ P(z)로 20만 개 이미지를 생성해서 보조 분류신경망으로 분류
- 분류기의 확실도(confidence)에 따라 샘플들을 정리해, 하위 50% 를 폐기
→ 100,000개의 라벨링된 latent-space vectors
- 각 특성attribute에 대해 선형 SVM를 학습시켜 latent space point에 따라 라벨을 예측하도록 함
- z for 기존
- w for style-based
- classify the points by this plane
- 조건부 엔트로피 H(Y|X) 계산
- X : SVM 이 예측한 클래스
- Y : 사전학습 분류기가 결정한 클래스
→ 샘플의 진짜 클래스를 결정하기 위해 얼마나 추가적인 정보가 필요한지 알게 됨 (hyperplance의 어느 면에 있는지 우리가 안다고 치고)
- a low value suggests consistent latent space directions for the corresponding factor(s) of variation
- 최종 분리가능성 스코어
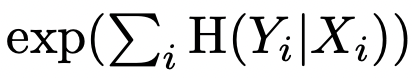
-
- i : 40개 특성
- exponentiation(제곱) : 값을 로그에서 선형적 영역으로 끌어와 비교하기 더 쉬워짐
- W가 일관적으로 Z보다 더 잘 분리될 수 있다. → 덜 entangled 됨
- 매핑 신경망이 깊어질수록 이미지 퀄리티와 W의 분리가능성이 더 좋아진다 ← 합성 신경망은 내재적으로 disentangled input을 선호한다.
- 기존 생성기 앞에 매핑 신경망을 추가하면 Z의 분리가능성은 아주 안 좋아지지만 중간 잠재 공간 W은 개선되고, FID도 좋아진다.
- 기존 생성기 아키텍처도 학습 데이터의 분포를 따를 필요가 없는 중간 잠재 공간을 도입했을 때 성능이 좋아지는 모습을 보임
'인공지능 > computer vision' 카테고리의 다른 글
| styleGAN2 이해하기 (0) | 2022.05.31 |
|---|---|
| StyleGAN1 vs. StyleGAN2 (0) | 2022.05.31 |
| PGGAN의 공식 코드 살펴보기 (0) | 2022.05.31 |
| PGGAN 이해하기 (0) | 2022.05.31 |
| DCGAN 이해하기 (0) | 2022.05.16 |