- pytorch colab Google Colaboratory
- tensorflow github GitHub - tkarras/progressive_growing_of_gans: Progressive Growing of GANs for Improved Quality, Stability, and Variation
networks.py 소스코드
- smooth fade in
# 선형보간 (linear interpolation)
def lerp(a, b, t):
return a + (b - a) * t
def lerp_clip(a, b, t):
return a + (b - a) * tf.clip_by_value(t, 0.0, 1.0) # [0, 1]의 텐서값이전 레이어의 값을 특정 비율만큼 반영해 부드럽게 고해상도 레이어를 추가할 수 있게 함
- convolutional/fully-connected layer
# fully-connected layer
def dense(x, fmaps, gain=np.sqrt(2), use_wscale=False):
if len(x.shape) > 2:
x = tf.reshape(x, [-1, np.prod([d.value for d in x.shape[1:]])])
w = get_weight([x.shape[1].value, fmaps], gain=gain, use_wscale=use_wscale)
w = tf.cast(w, x.dtype)
return tf.matmul(x, w)- 텐서 x의 차원이 2보다 클 경우,
*fmaps = feature maps
# convolutional layer
def conv2d(x, fmaps, kernel, gain=np.sqrt(2), use_wscale=False):
assert kernel >= 1 and kernel % 2 == 1
w = get_weight([kernel, kernel, x.shape[1].value, fmaps], gain=gain, use_wscale=use_wscale)
w = tf.cast(w, x.dtype)
return tf.nn.conv2d(x, w, strides=[1,1,1,1], padding='SAME', data_format='NCHW')- tf.nn.conv2d(x, w, …)
- x : [None, size, size, channel]
- w: [kernel, kernel, channel, outputs]
# 레이어 가중치를 구하기
def get_weight(shape, gain=np.sqrt(2), use_wscale=False, fan_in=None):
if fan_in is None:
fan_in = np.prod(shape[:-1])
std = gain / np.sqrt(fan_in) # He init
if use_wscale:
wscale = tf.constant(np.float32(std), name='wscale')
return tf.get_variable('weight', shape=shape, initializer=tf.initializers.random_normal()) * wscale
else:
return tf.get_variable('weight', shape=shape, initializer=tf.initializers.random_normal(0, std))
생성기(G)
def G_paper(
latents_in, # First input: Latent vectors [minibatch, latent_size].
labels_in, # Second input: Labels [minibatch, label_size].
num_channels = 1, # Number of output color channels. Overridden based on dataset.
resolution = 32, # Output resolution. Overridden based on dataset.
label_size = 0, # Dimensionality of the labels, 0 if no labels. Overridden based on dataset.
fmap_base = 8192, # Overall multiplier for the number of feature maps.
fmap_decay = 1.0, # log2 feature map reduction when doubling the resolution.
fmap_max = 512, # Maximum number of feature maps in any layer.
latent_size = None, # Dimensionality of the latent vectors. None = min(fmap_base, fmap_max).
normalize_latents = True, # Normalize latent vectors before feeding them to the network?
use_wscale = True, # Enable equalized learning rate?
use_pixelnorm = True, # Enable pixelwise feature vector normalization?
pixelnorm_epsilon = 1e-8, # Constant epsilon for pixelwise feature vector normalization.
use_leakyrelu = True, # True = leaky ReLU, False = ReLU.
dtype = 'float32', # Data type to use for activations and outputs.
fused_scale = True, # True = use fused upscale2d + conv2d, False = separate upscale2d layers.
structure = None, # 'linear' = human-readable, 'recursive' = efficient, None = select automatically.
is_template_graph = False, # True = template graph constructed by the Network class, False = actual evaluation.
**kwargs): # Ignore unrecognized keyword args.
resolution_log2 = int(np.log2(resolution))
assert resolution == 2**resolution_log2 and resolution >= 4
def nf(stage): return min(int(fmap_base / (2.0 ** (stage * fmap_decay))), fmap_max)
def PN(x): return pixel_norm(x, epsilon=pixelnorm_epsilon) if use_pixelnorm else x
if latent_size is None: latent_size = nf(0)
if structure is None: structure = 'linear' if is_template_graph else 'recursive'
act = leaky_relu if use_leakyrelu else tf.nn.relu
latents_in.set_shape([None, latent_size])
labels_in.set_shape([None, label_size])
combo_in = tf.cast(tf.concat([latents_in, labels_in], axis=1), dtype)
lod_in = tf.cast(tf.get_variable('lod', initializer=np.float32(0.0), trainable=False), dtype)
# Building blocks.
def block(x, res): # res = 2..resolution_log2
with tf.variable_scope('%dx%d' % (2**res, 2**res)):
if res == 2: # 4x4
if normalize_latents: x = pixel_norm(x, epsilon=pixelnorm_epsilon)
with tf.variable_scope('Dense'):
x = dense(x, fmaps=nf(res-1)*16, gain=np.sqrt(2)/4, use_wscale=use_wscale) # override gain to match the original Theano implementation
x = tf.reshape(x, [-1, nf(res-1), 4, 4])
x = PN(act(apply_bias(x)))
with tf.variable_scope('Conv'):
x = PN(act(apply_bias(conv2d(x, fmaps=nf(res-1), kernel=3, use_wscale=use_wscale))))
else: # 8x8 and up
if fused_scale:
with tf.variable_scope('Conv0_up'):
x = PN(act(apply_bias(upscale2d_conv2d(x, fmaps=nf(res-1), kernel=3, use_wscale=use_wscale))))
else:
x = upscale2d(x)
with tf.variable_scope('Conv0'):
x = PN(act(apply_bias(conv2d(x, fmaps=nf(res-1), kernel=3, use_wscale=use_wscale))))
with tf.variable_scope('Conv1'):
x = PN(act(apply_bias(conv2d(x, fmaps=nf(res-1), kernel=3, use_wscale=use_wscale))))
return x
def torgb(x, res): # res = 2..resolution_log2
lod = resolution_log2 - res
with tf.variable_scope('ToRGB_lod%d' % lod):
return apply_bias(conv2d(x, fmaps=num_channels, kernel=1, gain=1, use_wscale=use_wscale))
# Linear structure: simple but inefficient.
if structure == 'linear':
x = block(combo_in, 2)
images_out = torgb(x, 2)
for res in range(3, resolution_log2 + 1):
lod = resolution_log2 - res
x = block(x, res)
img = torgb(x, res)
images_out = upscale2d(images_out)
with tf.variable_scope('Grow_lod%d' % lod):
images_out = lerp_clip(img, images_out, lod_in - lod)
# Recursive structure: complex but efficient.
if structure == 'recursive':
def grow(x, res, lod):
y = block(x, res)
img = lambda: upscale2d(torgb(y, res), 2**lod)
if res > 2: img = cset(img, (lod_in > lod), lambda: upscale2d(lerp(torgb(y, res), upscale2d(torgb(x, res - 1)), lod_in - lod), 2**lod))
if lod > 0: img = cset(img, (lod_in < lod), lambda: grow(y, res + 1, lod - 1))
return img()
images_out = grow(combo_in, 2, resolution_log2 - 2)
assert images_out.dtype == tf.as_dtype(dtype)
images_out = tf.identity(images_out, name='images_out')
return images_out
- 인자로 받는 resolution : train 함수에서는 학습 데이터의 해상도를 넣는다.
- lod_in : ‘lod’ 라는 이름의 텐서 객체가 존재하는지 확인하고, 없으면 initializer로 새로 만든다. 단 lod는 학습되는 변수가 아님.
- block 함수
- if res == 2: 해상도 4 * 4
- pixel_norm : 잠재 벡터에서 픽셀단위로 정규화
- dense 레이어 + bias 적용 & LeakyRELU + 픽셀단위 정규화
- conv2d 레이어 + bias 적용 & LeakyRELU + 픽셀단위 정규화
- else: 해상도 8*8 이상
- fused_scale : True면 fused conv2d+downcale2d, False면 downscale2d
- upscale된 conv2d 레이어 + bias 적용 & LeakyRELU + 픽셀단위 정규화
- conv2d 레이어 + bias 적용 & LeakyRELU + 픽셀단위 정규화
- if res == 2: 해상도 4 * 4
- toRGB 함수
- resolution_log2에서 res를 뺀 것이 level of details가 됨
- conv2d 통과하고 bias 추가
- structure가 ‘linear’(선형)일 때랑 ‘recursive’(재귀)일 때가 있는데, 전자는 간단하지만 비효율적이고 후자는 복잡하지만 효율적이다. 여기서는 우선 전자로 살펴봄.
- combo_in이 block 함수 통과 후 toRGB 함수 통과
- for문 res 3부터 resolution_log2까지
- level of details를 resolution_log2 에서 res를 뺀 값으로 설정
- block 함수 통과 후 toRGB 함수 통과
- Nearest neighbor filtering을 활용한 upcaling 레이어 통과
- (lod_in - lod)를 clipping한 후 img와 upscaled된 이미지(images_out) 사이로 보간
식별기(D)
def D_paper(
images_in, # Input: Images [minibatch, channel, height, width].
num_channels = 1, # Number of input color channels. Overridden based on dataset.
resolution = 32, # Input resolution. Overridden based on dataset.
label_size = 0, # Dimensionality of the labels, 0 if no labels. Overridden based on dataset.
fmap_base = 8192, # Overall multiplier for the number of feature maps.
fmap_decay = 1.0, # log2 feature map reduction when doubling the resolution.
fmap_max = 512, # Maximum number of feature maps in any layer.
use_wscale = True, # Enable equalized learning rate?
mbstd_group_size = 4, # Group size for the minibatch standard deviation layer, 0 = disable.
dtype = 'float32', # Data type to use for activations and outputs.
fused_scale = True, # True = use fused conv2d + downscale2d, False = separate downscale2d layers.
structure = None, # 'linear' = human-readable, 'recursive' = efficient, None = select automatically
is_template_graph = False, # True = template graph constructed by the Network class, False = actual evaluation.
**kwargs): # Ignore unrecognized keyword args.
resolution_log2 = int(np.log2(resolution))
assert resolution == 2**resolution_log2 and resolution >= 4
def nf(stage): return min(int(fmap_base / (2.0 ** (stage * fmap_decay))), fmap_max)
if structure is None: structure = 'linear' if is_template_graph else 'recursive'
act = leaky_relu
images_in.set_shape([None, num_channels, resolution, resolution])
images_in = tf.cast(images_in, dtype)
lod_in = tf.cast(tf.get_variable('lod', initializer=np.float32(0.0), trainable=False), dtype)
# Building blocks.
def fromrgb(x, res): # res = 2..resolution_log2
with tf.variable_scope('FromRGB_lod%d' % (resolution_log2 - res)):
return act(apply_bias(conv2d(x, fmaps=nf(res-1), kernel=1, use_wscale=use_wscale)))
def block(x, res): # res = 2..resolution_log2
with tf.variable_scope('%dx%d' % (2**res, 2**res)):
if res >= 3: # 8x8 and up
with tf.variable_scope('Conv0'):
x = act(apply_bias(conv2d(x, fmaps=nf(res-1), kernel=3, use_wscale=use_wscale)))
if fused_scale:
with tf.variable_scope('Conv1_down'):
x = act(apply_bias(conv2d_downscale2d(x, fmaps=nf(res-2), kernel=3, use_wscale=use_wscale)))
else:
with tf.variable_scope('Conv1'):
x = act(apply_bias(conv2d(x, fmaps=nf(res-2), kernel=3, use_wscale=use_wscale)))
x = downscale2d(x)
else: # 4x4
if mbstd_group_size > 1:
x = minibatch_stddev_layer(x, mbstd_group_size)
with tf.variable_scope('Conv'):
x = act(apply_bias(conv2d(x, fmaps=nf(res-1), kernel=3, use_wscale=use_wscale)))
with tf.variable_scope('Dense0'):
x = act(apply_bias(dense(x, fmaps=nf(res-2), use_wscale=use_wscale)))
with tf.variable_scope('Dense1'):
x = apply_bias(dense(x, fmaps=1+label_size, gain=1, use_wscale=use_wscale))
return x
# Linear structure: simple but inefficient.
if structure == 'linear':
img = images_in
x = fromrgb(img, resolution_log2)
for res in range(resolution_log2, 2, -1):
lod = resolution_log2 - res
x = block(x, res)
img = downscale2d(img)
y = fromrgb(img, res - 1)
with tf.variable_scope('Grow_lod%d' % lod):
x = lerp_clip(x, y, lod_in - lod)
combo_out = block(x, 2)
# Recursive structure: complex but efficient.
if structure == 'recursive':
def grow(res, lod):
x = lambda: fromrgb(downscale2d(images_in, 2**lod), res)
if lod > 0: x = cset(x, (lod_in < lod), lambda: grow(res + 1, lod - 1))
x = block(x(), res); y = lambda: x
if res > 2: y = cset(y, (lod_in > lod), lambda: lerp(x, fromrgb(downscale2d(images_in, 2**(lod+1)), res - 1), lod_in - lod))
return y()
combo_out = grow(2, resolution_log2 - 2)
assert combo_out.dtype == tf.as_dtype(dtype)
scores_out = tf.identity(combo_out[:, :1], name='scores_out')
labels_out = tf.identity(combo_out[:, 1:], name='labels_out')
return scores_out, labels_out- 첫번째 images_in 인자는 [미니배치, 채널, 높이, 가로] 의 모양으로 되어 있다.
- image_in의 모양을 셋팅
- fromRGB 함수 : conv2d 통과 후 bias 적용, LeakyRELU
- block 함수
- res >= 3 해상도가 8*8 이상이면
- conv2d 통과 후 bias 적용, LeakyRELU
- fused_scale 이 True면 conv2d_downscaled2d 통과 후 bias 적용, LeakyRELU, False면 conv2d 통과 후 bias 적용, LeakyRELU 통과 후 downscaled2d 통과
- else 해상도가 4*4이면
- mbstd_group_size (미니배치 표준편차 레이어를 위한 group size)가 1보다 크고, minibatch_stddev_layer로 미니배치에 대한 feature statistics 계산.
- 그 값으로 conv2d, dense, dense (마지막 dense 레이어는 활성화 함수 비적용) 통과
- res >= 3 해상도가 8*8 이상이면
- structure가 ‘linear’(선형)일 때랑 ‘recursive’(재귀)일 때가 있는데, 전자는 간단하지만 비효율적이고 후자는 복잡하지만 효율적이다. 여기서는 우선 전자로 살펴봄.
- image_in이 fromRGB 함수 통과
- for문 res resolution_log2부터 3까지
- level of details를 resolution_log2 에서 res를 뺀 값으로 설정
- block , dwonscaled2d 통과한 결과 x가 됨
- (lod_in - lod)를 clipping한 후 x와 downscaled된 y 사이로 보간
- for문 마쳤으면 마지막 x를 block에 통과해서 combo_out
- combo_out[:, :1]은 scores_out이 되고 combo_out[:, 1:]은 labels_out이 됨
학습 소스코드
# Main training script.
# To run, comment/uncomment appropriate lines in config.py and launch train.py.
def train_progressive_gan(
G_smoothing = 0.999, # Exponential running average of generator weights.
D_repeats = 1, # How many times the discriminator is trained per G iteration.
minibatch_repeats = 4, # Number of minibatches to run before adjusting training parameters.
reset_opt_for_new_lod = True, # Reset optimizer internal state (e.g. Adam moments) when new layers are introduced?
total_kimg = 15000, # Total length of the training, measured in thousands of real images.
mirror_augment = False, # Enable mirror augment?
drange_net = [-1,1], # Dynamic range used when feeding image data to the networks.
image_snapshot_ticks = 1, # How often to export image snapshots?
network_snapshot_ticks = 10, # How often to export network snapshots?
save_tf_graph = False, # Include full TensorFlow computation graph in the tfevents file?
save_weight_histograms = False, # Include weight histograms in the tfevents file?
resume_run_id = None, # Run ID or network pkl to resume training from, None = start from scratch.
resume_snapshot = None, # Snapshot index to resume training from, None = autodetect.
resume_kimg = 0.0, # Assumed training progress at the beginning. Affects reporting and training schedule.
resume_time = 0.0): # Assumed wallclock time at the beginning. Affects reporting.
maintenance_start_time = time.time()
training_set = dataset.load_dataset(data_dir=config.data_dir, verbose=True, **config.dataset)- PGGAN 을 학습시키는 train_progressive_gan 함수
신경망 구성하기
# Construct networks.
with tf.device('/gpu:0'):
if resume_run_id is not None:
network_pkl = misc.locate_network_pkl(resume_run_id, resume_snapshot)
print('Loading networks from "%s"...' % network_pkl)
G, D, Gs = misc.load_pkl(network_pkl)
else:
print('Constructing networks...')
G = tfutil.Network('G', num_channels=training_set.shape[0], resolution=training_set.shape[1], label_size=training_set.label_size, **config.G)
D = tfutil.Network('D', num_channels=training_set.shape[0], resolution=training_set.shape[1], label_size=training_set.label_size, **config.D)
Gs = G.clone('Gs')
Gs_update_op = Gs.setup_as_moving_average_of(G, beta=G_smoothing)
G.print_layers(); D.print_layers()- with tf.device('/gpu:0'): 첫번째 GPU 지정
- 신경망을 처음부터(start from scratch) 구성하는 것이므로 else : tfutil에 정의된 Network 클래스 객체 생성
- name, num_channels, resolution, label_size, config.G/config.D (딕셔너리 {func:'networks.G_paper'}, {func:'networks.G_paper'})
- → networks.py 에 정의된 G_paper / D_paper
- Gs 로 객체 복제 : Network 클래스의 clone 함수
def clone(self, name=None):
net = object.__new__(Network)
net._init_fields()
net.name = name if name is not None else self.name
net.static_kwargs = dict(self.static_kwargs)
net._build_module_src = self._build_module_src
net._build_func_name = self._build_func_name
net._build_func = self._build_func
net._init_graph()
net.copy_vars_from(self)
return netnet = object.__new__(Network) : 초기값(init)이 없는 Network 객체 생성
- _init_fields()로 초기값을 초기화한 후, _build_module_src, _build_func_name, _build_func 를 그대로 가져온다 (몇 개 값만 복제해 쓰기 위해 이렇게 하는 것 같다)
세 개의 신경망 객체(G, D, Gs)가 준비되면, 신경망의 변수를 업데이트하는 텐서플로우 오퍼레이션(TensorFlow op)을 구성한다
- Network 클래스 객체 Gs(cloned)의 setup_as_moving_average_of 함수 (이동평균)
def setup_as_moving_average_of(self, src_net, beta=0.99, beta_nontrainable=0.0):
assert isinstance(src_net, Network)
with absolute_name_scope(self.scope):
with tf.name_scope('MovingAvg'):
ops = []
for name, var in self.vars.items():
if name in src_net.vars:
cur_beta = beta if name in self.trainables else beta_nontrainable
new_value = lerp(src_net.vars[name], var, cur_beta)
ops.append(var.assign(new_value))
return tf.group(*ops)- beta = G_smoothing 즉 0.999
- 받아온 src_net , 즉 G가 Network 클래스의 객체일 때
- ( absolute_name_scope : 뒤에 '/' 붙여 강제로 네임스코프 지정 )
- Gs_update_op
- Gs의 변수들, self.vars 는 {‘변수명’:변수내용}으로 된 OrderedDict
- 이 변수 중에서 G에 있는 변수라면,
- cur_beta : 학습될 파라미터라면 beta(0.999)로 설정하고, 아니라면 beta_nontrainable(0.0)으로 설정
- new_value : G 변수에서 Gs 변수까지 cur_beta 비율만큼 업데이트한 값 추가
print('Building TensorFlow graph...')
with tf.name_scope('Inputs'):
lod_in = tf.placeholder(tf.float32, name='lod_in', shape=[])
lrate_in = tf.placeholder(tf.float32, name='lrate_in', shape=[])
minibatch_in = tf.placeholder(tf.int32, name='minibatch_in', shape=[])
minibatch_split = minibatch_in // config.num_gpus
reals, labels = training_set.get_minibatch_tf()
reals_split = tf.split(reals, config.num_gpus)
labels_split = tf.split(labels, config.num_gpus)- 텐서플로우 그래프 생성
- 이름 ‘Inputs’ 아래 여러 변수를 준비
- placeholder for lod_in, lrate_in, minibatch_in
- gpu 개수만큼 minibatch 나누기
- 다음 minibatch의 이미지와 라벨을 가져오고 각각 gpu 개수만큼 나누기
G_opt = tfutil.Optimizer(name='TrainG', learning_rate=lrate_in, **config.G_opt)
D_opt = tfutil.Optimizer(name='TrainD', learning_rate=lrate_in, **config.D_opt)
for gpu in range(config.num_gpus):
with tf.name_scope('GPU%d' % gpu), tf.device('/gpu:%d' % gpu):
G_gpu = G if gpu == 0 else G.clone(G.name + '_shadow')
D_gpu = D if gpu == 0 else D.clone(D.name + '_shadow')
lod_assign_ops = [tf.assign(G_gpu.find_var('lod'), lod_in), tf.assign(D_gpu.find_var('lod'), lod_in)]
reals_gpu = process_reals(reals_split[gpu], lod_in, mirror_augment, training_set.dynamic_range, drange_net)
labels_gpu = labels_split[gpu]
with tf.name_scope('G_loss'), tf.control_dependencies(lod_assign_ops):
G_loss = tfutil.call_func_by_name(G=G_gpu, D=D_gpu, opt=G_opt, training_set=training_set, minibatch_size=minibatch_split, **config.G_loss)
with tf.name_scope('D_loss'), tf.control_dependencies(lod_assign_ops):
D_loss = tfutil.call_func_by_name(G=G_gpu, D=D_gpu, opt=D_opt, training_set=training_set, minibatch_size=minibatch_split, reals=reals_gpu, labels=labels_gpu, **config.D_loss)
G_opt.register_gradients(tf.reduce_mean(G_loss), G_gpu.trainables)
D_opt.register_gradients(tf.reduce_mean(D_loss), D_gpu.trainables)
G_train_op = G_opt.apply_updates()
D_train_op = D_opt.apply_updates()*lod = level of detail (레이어가 더해질수록 디테일해지니까)
- tfutil.py 의 Optimizer 클래스 객체 생성 : 같은 학습률, config.G_opt / config.D_opt (딕셔너리 {func='loss.G_wgan_acgan'} / {func='loss.D_wgangp_acgan'})
- loss.py에 정의된 손실함수 [학부생의 딥러닝] GANs | WGAN, WGAN-GP : Wassestein GAN(Gradient Penalty)
- G_wgan_acgan (WGAN + AC-GAN)
def G_wgan_acgan(G, D, opt, training_set, minibatch_size,
cond_weight = 1.0): # Weight of the conditioning term.
...- D_gangp_acgan (WGAN-GP + AC-GAN)
def D_wgangp_acgan(G, D, opt, training_set, minibatch_size, reals, labels,
wgan_lambda = 10.0, # Weight for the gradient penalty term.
wgan_epsilon = 0.001, # Weight for the epsilon term, \epsilon_{drift}.
wgan_target = 1.0, # Target value for gradient magnitudes.
cond_weight = 1.0): # Weight of the conditioning terms.
...
- gpu 하나씩 반복
- 첫번째 gpu일 때 G, D 그대로 사용, 그 이후는 clone
- lod_assign_ops: 변수를 name으로 찾아 지역/전역 변수 할당 (to the placeholder)
- process_reals: 신경망에 먹이기 전 학습이미지를 JIT로 처리, dynamic range 조정 → smoothly fade in
- reals_split[gpu] :해당 GPU에 할당된 학습이미지 묶음
- lod_in : 기존 해상도에서 upscale하면서 lod - tf.floor(lod) 비율만큼 lerp
- mirror_augment (boolean) : false
- training_set.dynamic_range : [0, 255]
- drange_net : [-1, 1]
- G_loss, D_loss :G, D의 loss 함수를 호출하여 손실을 구한다
- Optimizer 객체의 register_gradients 함수: 주어진 손실함수(tf.reduce_mean(G_loss)/tf.reduce_mean(D_loss))의 gradient를 계산해 각 변수(G_gpu.trainables, D_gpu.trainables)에 적용
- GPU 당 한 번만 시행; _updates_applied 는 False로 아직 업데이트 되지 않았음을 flag 표시
- apply_loss_scaling로 loss 스케일 후(equalized learning rate), Adam 옵티마이저로 compute_gradients 실행. 구해지지 않은 gradient는 0으로 채움.
- apply_updates: GPU 모두 사용해 gradient 계산했으면, 변수 업데이트
- self._updates_applied = True 로 업데이트 되었음을 표시
- device별로 gradient의 partial sum을 구함
- device에 걸쳐 변수별로 gradient sum
- 각 device에 업데이트 적용
print('Training...')
cur_nimg = int(resume_kimg * 1000)
cur_tick = 0
tick_start_nimg = cur_nimg
tick_start_time = time.time()
train_start_time = tick_start_time - resume_time
prev_lod = -1.0
while cur_nimg < total_kimg * 1000:
# Choose training parameters and configure training ops.
sched = TrainingSchedule(cur_nimg, training_set, **config.sched)
training_set.configure(sched.minibatch, sched.lod)
if reset_opt_for_new_lod:
if np.floor(sched.lod) != np.floor(prev_lod) or np.ceil(sched.lod) != np.ceil(prev_lod):
G_opt.reset_optimizer_state(); D_opt.reset_optimizer_state()
prev_lod = sched.lod- 학습스케줄 TrainingSchedule 객체 sched 생성
- 주어진 minibatch와 lod를 현재 미니배치와 level of details로 설정
- reset_opt_for_new_lod : 새로운 레이어가 추가될 때(sched.lod와 prev_lod가 같지 않을 때) 옵티마이저를 내부적으로 리셋한다
- prev_lod를 sched.lod로 설정
# Run training ops.
for repeat in range(minibatch_repeats):
for _ in range(D_repeats):
tfutil.run([D_train_op, Gs_update_op], {lod_in: sched.lod, lrate_in: sched.D_lrate, minibatch_in: sched.minibatch})
cur_nimg += sched.minibatch
tfutil.run([G_train_op], {lod_in: sched.lod, lrate_in: sched.G_lrate, minibatch_in: sched.minibatch})- 학습 오퍼레이션 실행
- minibatch_repeats : 학습 파라미터 조절 전에 실행시킬 미니배치의 개수
- D_repeats : 생성기 한 번 학습할 때마다 식별기는 몇 번 학습시키는지
- tfutil.run : 학습 오퍼레이션 session 실행
- D_repeats 만큼 식별기 학습시키면 다음으로 생성기 학습
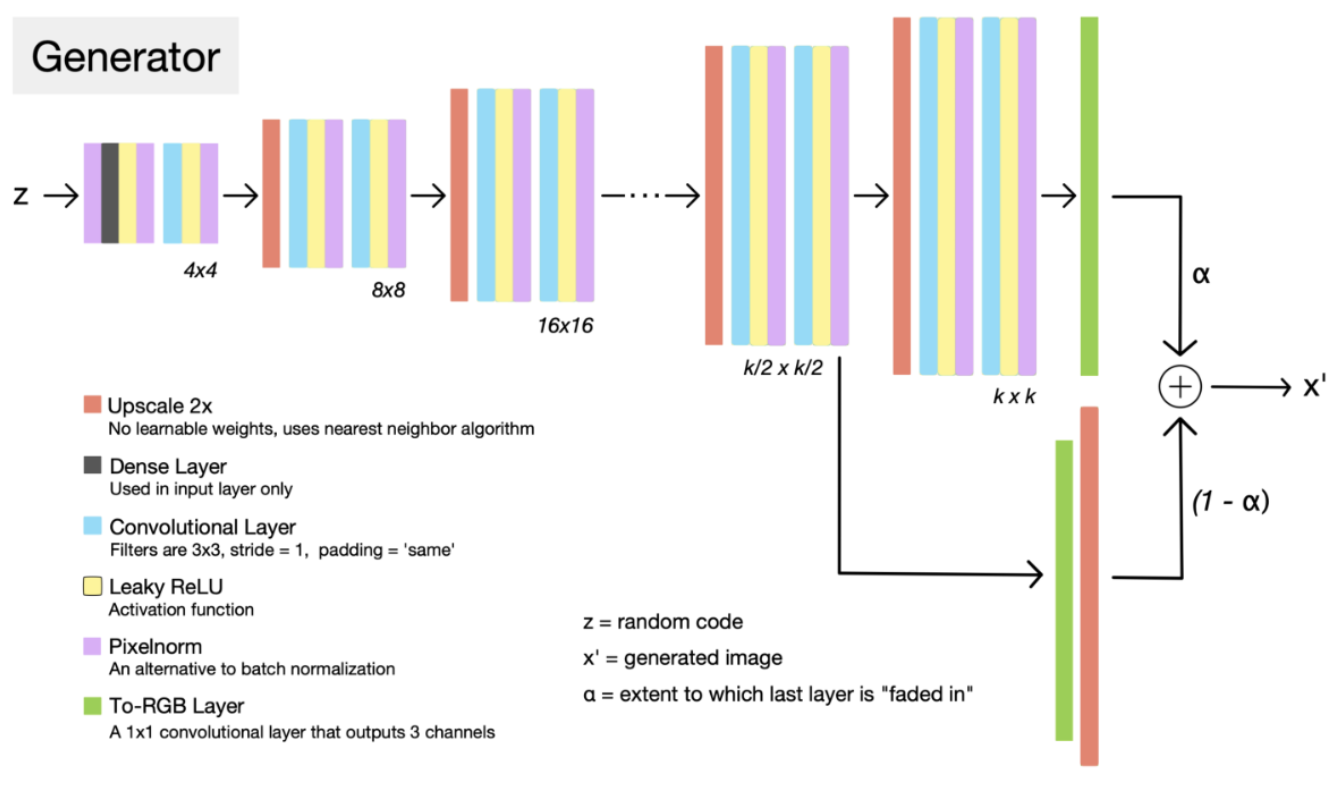
G_paper: progressive part
처음 해상도 4*4 에서 images out 만들고, 8 * 8 해상도부터 (resolution_log2 까지) for문으로 반복하며 images_out 업데이트!!
- 해상도 4 * 4 (처음)
- pixel normalization
- dense + bias + activation
- pixel normalization
- conv + bias + activation
- pixel normalization (toRGB) => images_out
- 해상도 8 * 8
- upscale
- conv + bias + activation
- pixel normalization
- conv + bias (toRGB) => img
- 앞서 구한 images_out에 upscale
- img 와 images_out의 lerp_clip => images_out
- 해상도 16 * 16
- upscale
- conv + bias + activation
- pixel normalization
- conv + bias (toRGB) => img
- 앞서 구한 images_out에 upscale
- img 와 images_out의 lerp_clip => images_out
'인공지능 > computer vision' 카테고리의 다른 글
| StyleGAN1 vs. StyleGAN2 (0) | 2022.05.31 |
|---|---|
| styleGAN 이해하기 (0) | 2022.05.31 |
| PGGAN 이해하기 (0) | 2022.05.31 |
| DCGAN 이해하기 (0) | 2022.05.16 |
| GAN 이해하기 (0) | 2022.05.15 |