styleGAN ver1 vs. styleGAN ver2

<주요 특징>
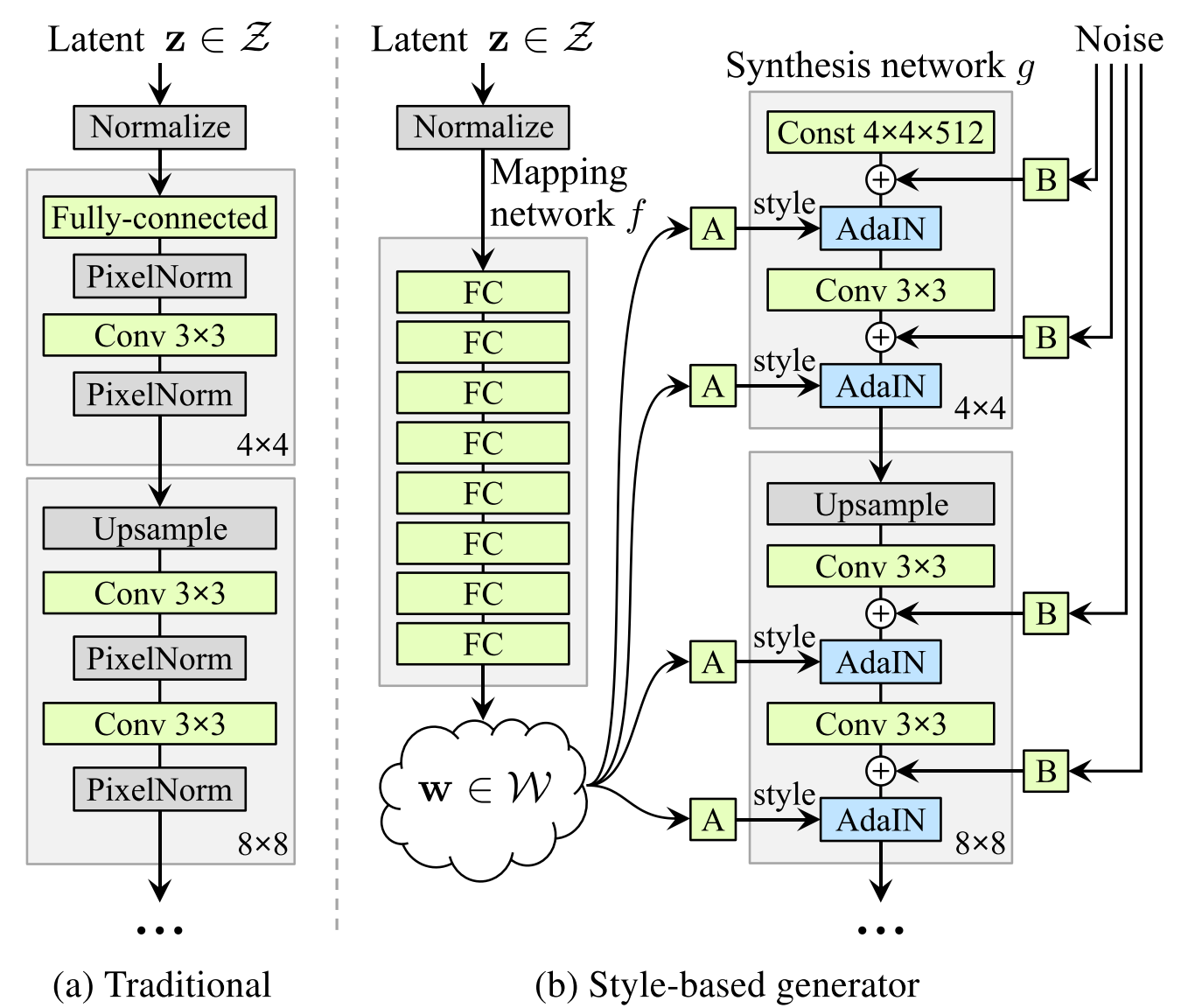
styleGAN : mapping network, AdaIN, Noise
styleGAN2 : AdaIN 연산 수정, progressive 대신에 G output skips, D residual nets
styleGAN 의 mapping network는 networks_stylegan.py의 G_style 함수로, synthesis network는 G_synthesis 함수로 정의된다 (보다 정확히 말하자면, Style-based generator는 G_mapping과 G_synthesis라는 두 서브 네트워크로 이루어진다.)
G_synthesis에서 이미지를 합성하는 부분(해상도 2x 하며 images_out 업데이트)은 PGGAN과 거의 동일하다.
- Early layers ( 4 * 4 해상도 )
- 합성 네트워크로 바로 입력되는 상수 벡터라면 곧바로 layer_epilogue 함수로 들어가서 노이즈 추가, bias, 활성화함수, pixel/instance 정규화, AdaIN 적용
- 잠재코드 w 라면, dense 통과 후 layer_epilogue 함수로 들어가서 노이즈 추가, bias, 활성화함수, pixel/instance 정규화, AdaIN 적용
- 그 다음 conv 레이어를 통과하고, layer_epilogue로 다시 들어간다 .. 노이즈 추가, bias, 활성화함수, pixel/instance 정규화, AdaIN 적용
# Early layers.
with tf.variable_scope('4x4'):
if const_input_layer:
with tf.variable_scope('Const'):
x = tf.get_variable('const', shape=[1, nf(1), 4, 4], initializer=tf.initializers.ones())
x = layer_epilogue(tf.tile(tf.cast(x, dtype), [tf.shape(dlatents_in)[0], 1, 1, 1]), 0)
else:
with tf.variable_scope('Dense'):
x = dense(dlatents_in[:, 0], fmaps=nf(1)*16, gain=gain/4, use_wscale=use_wscale) # tweak gain to match the official implementation of Progressing GAN
x = layer_epilogue(tf.reshape(x, [-1, nf(1), 4, 4]), 0)
with tf.variable_scope('Conv'):
x = layer_epilogue(conv2d(x, fmaps=nf(1), kernel=3, gain=gain, use_wscale=use_wscale), 1)
####################################################################################################################################################################
# Linear structure: simple but inefficient.
if structure == 'linear':
images_out = torgb(2, x)
for res in range(3, resolution_log2 + 1):
lod = resolution_log2 - res
x = block(res, x)
img = torgb(res, x)
images_out = upscale2d(images_out)
with tf.variable_scope('Grow_lod%d' % lod):
images_out = tflib.lerp_clip(img, images_out, lod_in - lod)layer_epilogue: noise 적용, instance normalization, Style modulation
*해상도마다 block 함수를 통과하므로 해상도 레이어마다 noise, style modulation 적용됨
style modulation = AdaIN !!!
content input인 x와 style input인 y를 평균과 분산으로 정규화
dense를 통과해서 나온 style 에 ys, yb 가 있음
def style_mod(x, dlatent, **kwargs):
with tf.variable_scope('StyleMod'):
style = apply_bias(dense(dlatent, fmaps=x.shape[1]*2, gain=1, **kwargs))
style = tf.reshape(style, [-1, 2, x.shape[1]] + [1] * (len(x.shape) - 2))
return x * (style[:,0] + 1) + style[:,1]
(코세라) AdaIN은 각 conv 레이어 다음에 있고, dlatent w도 AdaIN으로 들어간다.
step1. Instance Normalization : batch 단위로 정규화하지 않고 instance 단위로 정규화.
step2. apply adaptive styles : dlatent w는 학습된 dense 레이어를 통과해 ys(scale), yb(bias)로 나온다. 이 statistics가 AdaIN layers에 적용된다. ys는 rescale 하고, yb는 reshift 함.
→ instance씩 0~1 사이로 정규화된 값을 스케일링하고 shift 하기 = content에 style 적용하기
G_mapping
# Normalize latents.
if normalize_latents:
x = pixel_norm(x)
# Mapping layers.
for layer_idx in range(mapping_layers):
with tf.variable_scope('Dense%d' % layer_idx):
fmaps = dlatent_size if layer_idx == mapping_layers - 1 else mapping_fmaps
x = dense(x, fmaps=fmaps, gain=gain, use_wscale=use_wscale, lrmul=mapping_lrmul)
x = apply_bias(x, lrmul=mapping_lrmul)
x = act(x)Latent vectors Z를 pixel normalization하고, 8개의 mapping layer로 이루어진 MLP 를 통과한다.
G_style 아래 서브 네트워크인 G_mapping과 G_synthesis 를 세팅하는 부분
# Setup components.
if 'synthesis' not in components:
components.synthesis = tflib.Network('G_synthesis', func_name=G_synthesis, **kwargs)
num_layers = components.synthesis.input_shape[1]
dlatent_size = components.synthesis.input_shape[2]
if 'mapping' not in components:
components.mapping = tflib.Network('G_mapping', func_name=G_mapping, dlatent_broadcast=num_layers, **kwargs)
G_mapping → G_synthesis
- latents_in (z) 가 mapping 네트워크를 통과해 disentangled latents (w) 로 나온다
dlatents = components.mapping.get_output_for(latents_in, labels_in, **kwargs)2. dlatent_avg_beta만큼 (이동평균을 구할 때 오래된 데이터의 영향을 감쇠시키는 정도), 이동평균 업데이트. style_mixing_prob만큼 mixing regularization. truncation_psi 만큼 truncation trick.
# Update moving average of W.
if dlatent_avg_beta is not None:
with tf.variable_scope('DlatentAvg'):
batch_avg = tf.reduce_mean(dlatents[:, 0], axis=0)
update_op = tf.assign(dlatent_avg, tflib.lerp(batch_avg, dlatent_avg, dlatent_avg_beta))
with tf.control_dependencies([update_op]):
dlatents = tf.identity(dlatents)
if style_mixing_prob is not None:
with tf.name_scope('StyleMix'):
latents2 = tf.random_normal(tf.shape(latents_in))
dlatents2 = components.mapping.get_output_for(latents2, labels_in, **kwargs)
layer_idx = np.arange(num_layers)[np.newaxis, :, np.newaxis]
cur_layers = num_layers - tf.cast(lod_in, tf.int32) * 2
mixing_cutoff = tf.cond(
tf.random_uniform([], 0.0, 1.0) < style_mixing_prob,
lambda: tf.random_uniform([], 1, cur_layers, dtype=tf.int32),
lambda: cur_layers)
dlatents = tf.where(tf.broadcast_to(layer_idx < mixing_cutoff, tf.shape(dlatents)), dlatents, dlatents2)
# Apply truncation trick.
if truncation_psi is not None and truncation_cutoff is not None:
with tf.variable_scope('Truncation'):
layer_idx = np.arange(num_layers)[np.newaxis, :, np.newaxis]
ones = np.ones(layer_idx.shape, dtype=np.float32)
coefs = tf.where(layer_idx < truncation_cutoff, truncation_psi * ones, ones)
dlatents = tflib.lerp(dlatent_avg, dlatents, coefs)3. 잠재코드 dlatents를 G_synthesis에 입력해 이미지를 생성한다
# Evaluate synthesis network.
with tf.control_dependencies([tf.assign(components.synthesis.find_var('lod'), lod_in)]):
images_out = components.synthesis.get_output_for(dlatents, force_clean_graph=is_template_graph, **kwargs)
return tf.identity(images_out, name='images_out')'인공지능 > computer vision' 카테고리의 다른 글
| styleGAN3 이해하기 (0) | 2022.08.01 |
|---|---|
| styleGAN2 이해하기 (0) | 2022.05.31 |
| styleGAN 이해하기 (0) | 2022.05.31 |
| PGGAN의 공식 코드 살펴보기 (0) | 2022.05.31 |
| PGGAN 이해하기 (0) | 2022.05.31 |