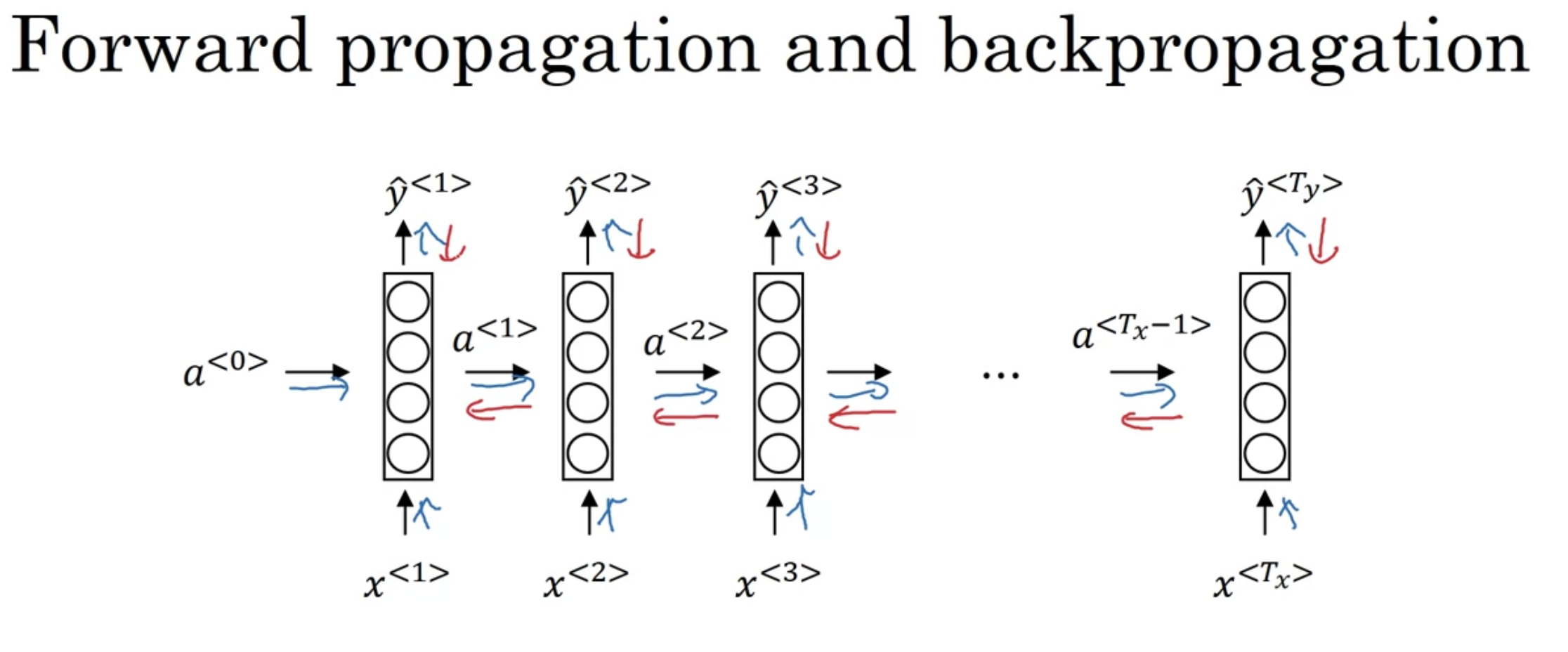
Backpropagation Through Time
반대 순서로 연산한다고 생각
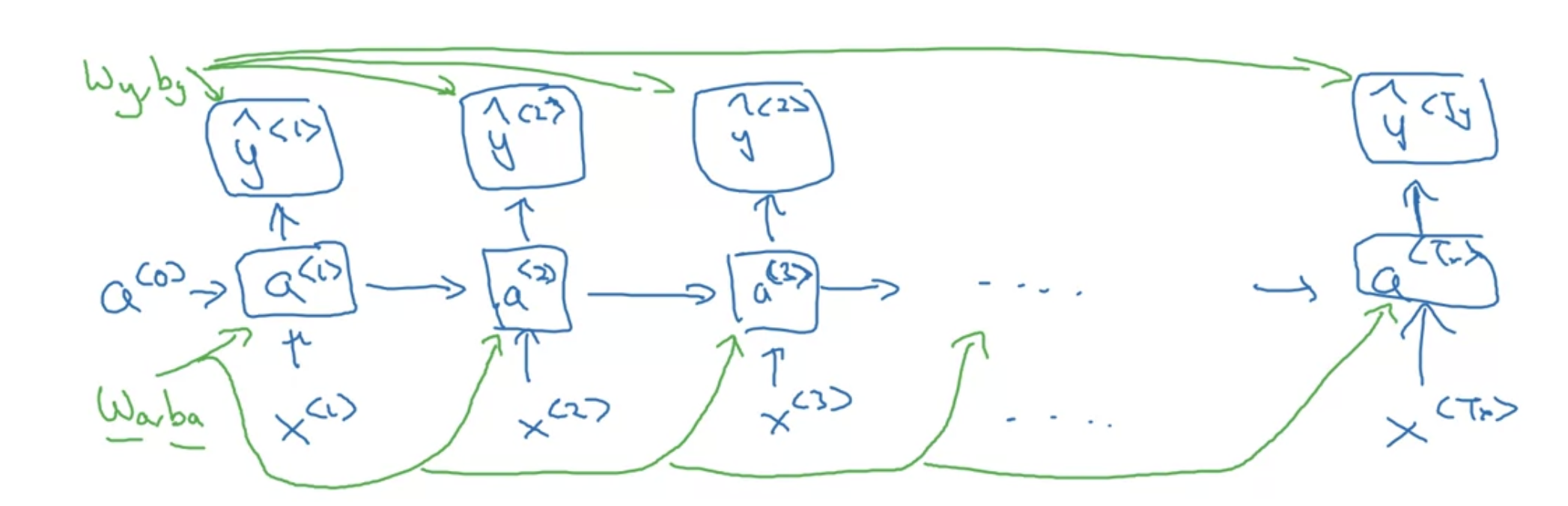
파라미터들 ($w_{a}$, $b_{a}$, $w_{y}$, $b_{y}$) 공유한다는 점 잊지 말기
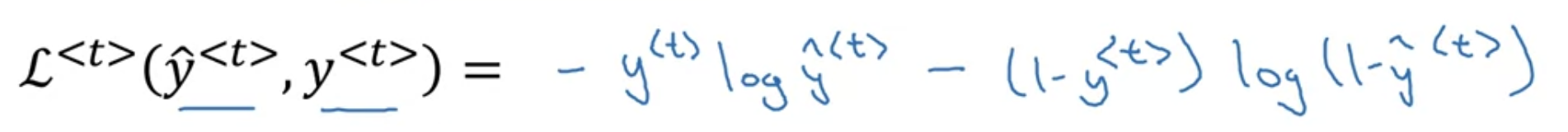
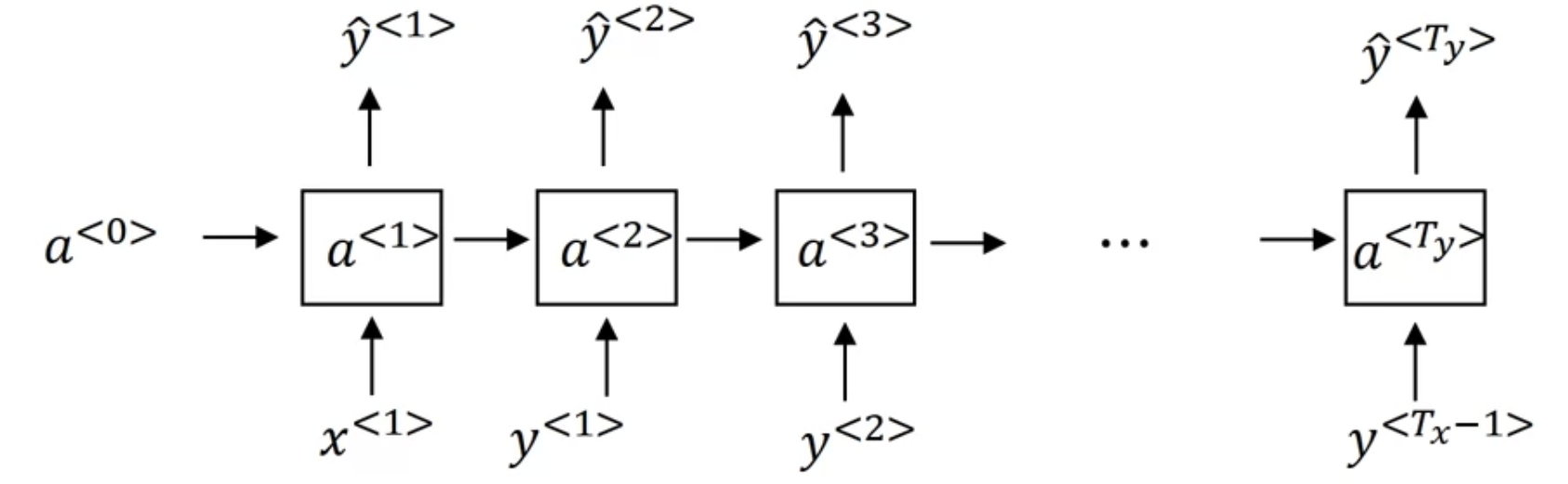
a single prediction at a single position(at a single time set)
전체 시퀀스에 대해서는?
$$L(\hat{y}, y) = \sum_{t=1}^{T_{x}} L^{<t>}(\hat{y}^{<t>}, y^{<t>})$$
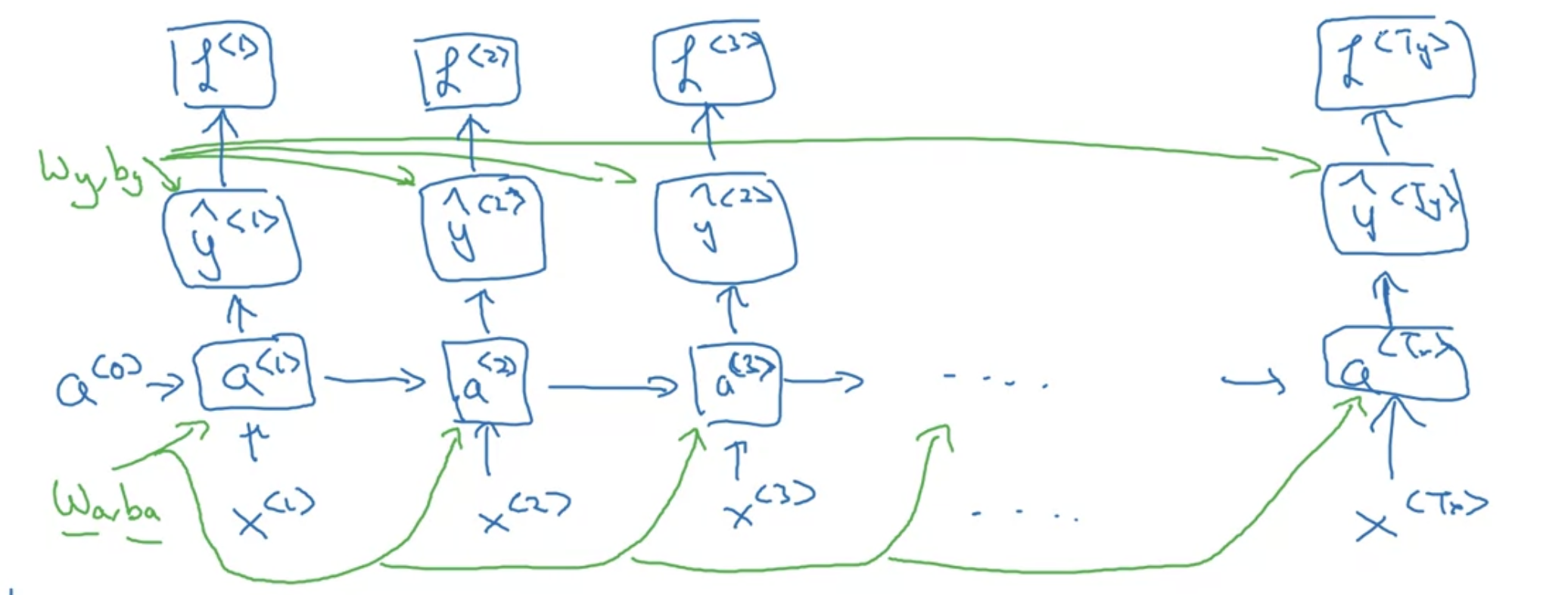
time step마다 loss를 구할 수 있음 -> 다 더하면 최종 $L$
이 과정을 전부 거꾸로 -> derivatives 구해서 파라미터 업데이트 - back prop하는 건 크게 다르지 않음
time step을 거꾸로 타고 흐르는 back prop이 핵심 -> "backpropagation through time" 이라는 fancy한 이름도 있다
Different types of RNNs
- input $x$와 output $y$ 는 다양한 타입일 수 있다
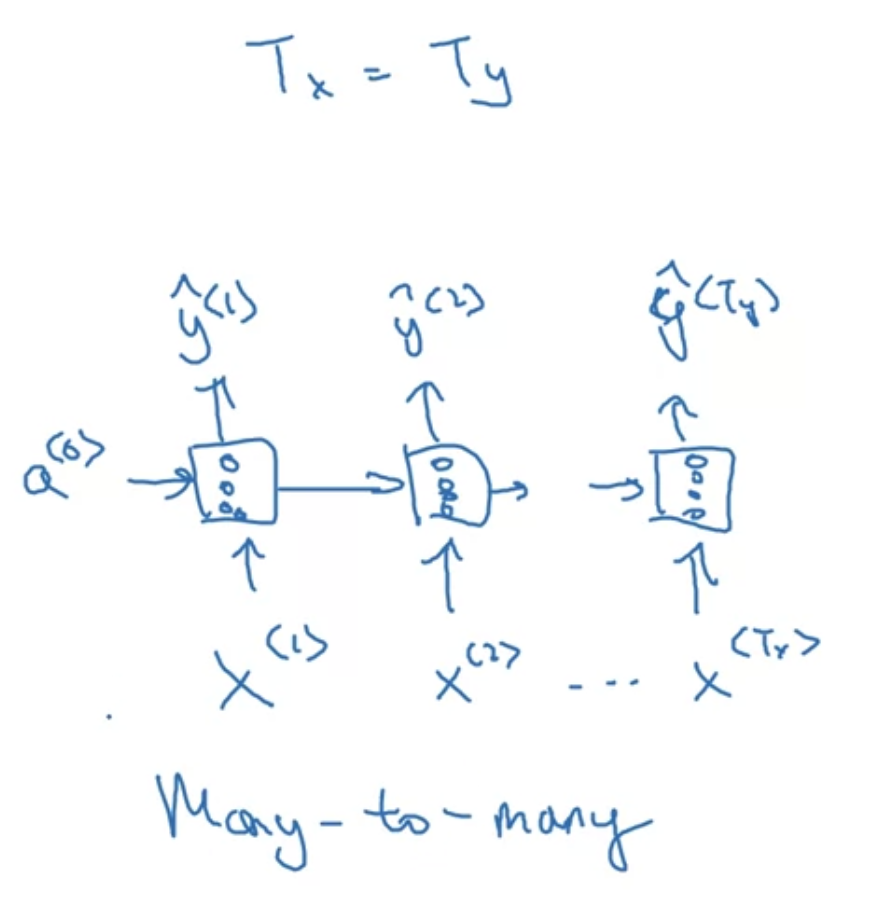
- 늘 $T_{x} = T_{y}$인 것도 아님
이 아티클 기반의 강의라고 함
[Examples of RNN architectures]
지금까지 살펴본 예시 : many-to-many
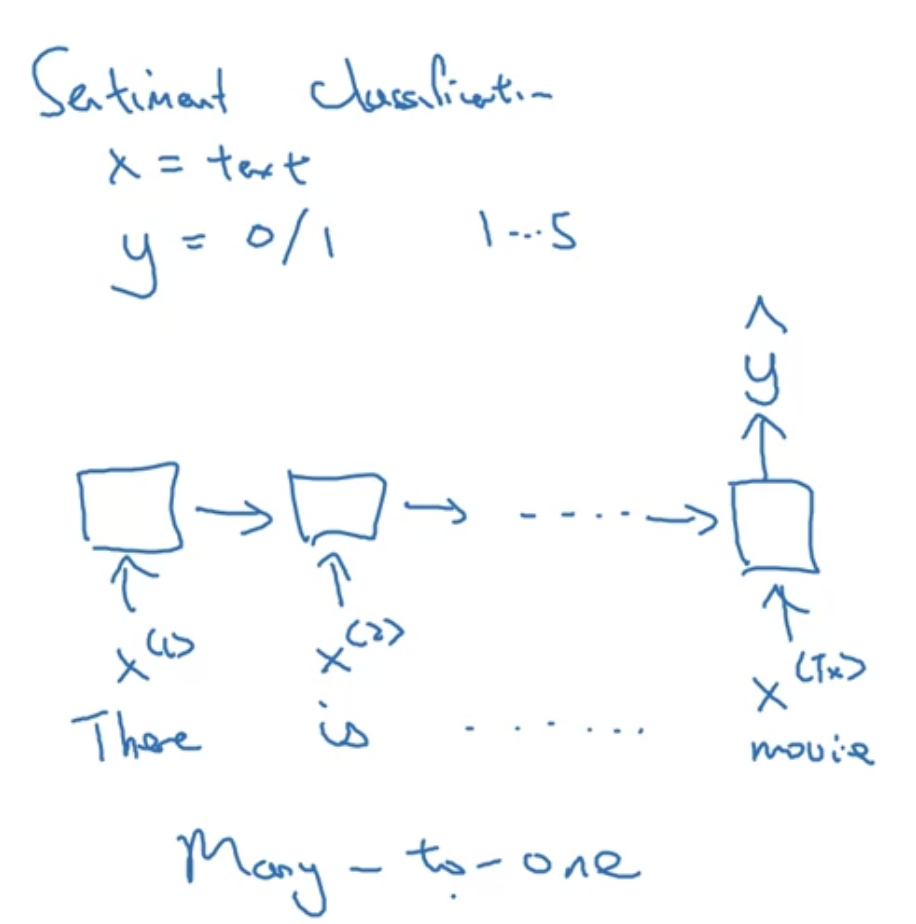
- 감성 분류한다고 쳤을 때, 텍스트를 입력하고 긍부정이나 별점 1~5점을 출력할 수 있음 이 경우에는,
Many-to-one
one-to-one 도 있는데 이전에 다룬 네트워크들과 다를 바 없고 uninteresting 함
one-to-many
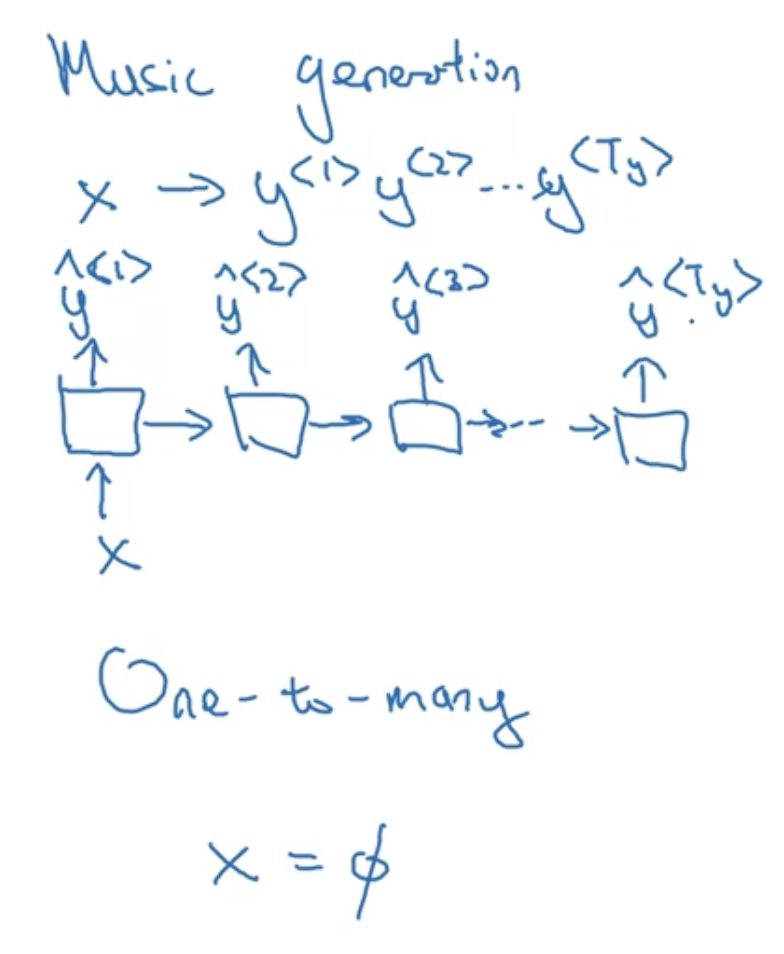
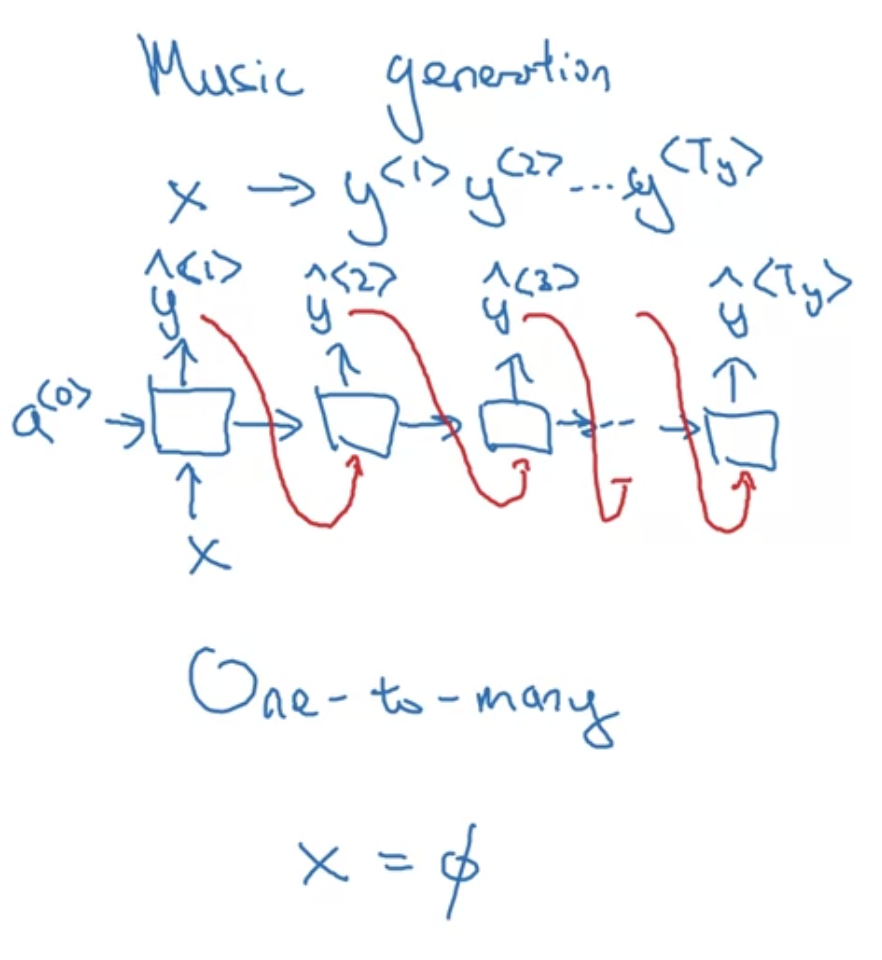
입력 $x$는 아예 없거나 정수 하나짜리일 수도 있음
music generation
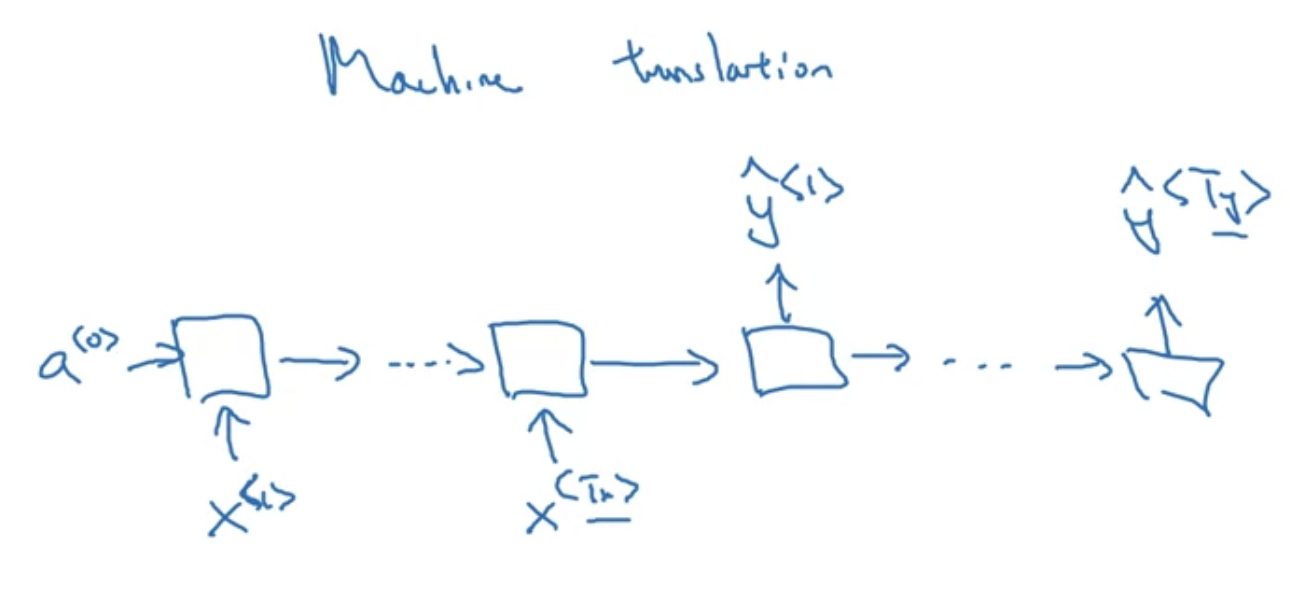
$T_{x}$와 $T_{y}$가 다른 many-to-many 사례
- machine translation
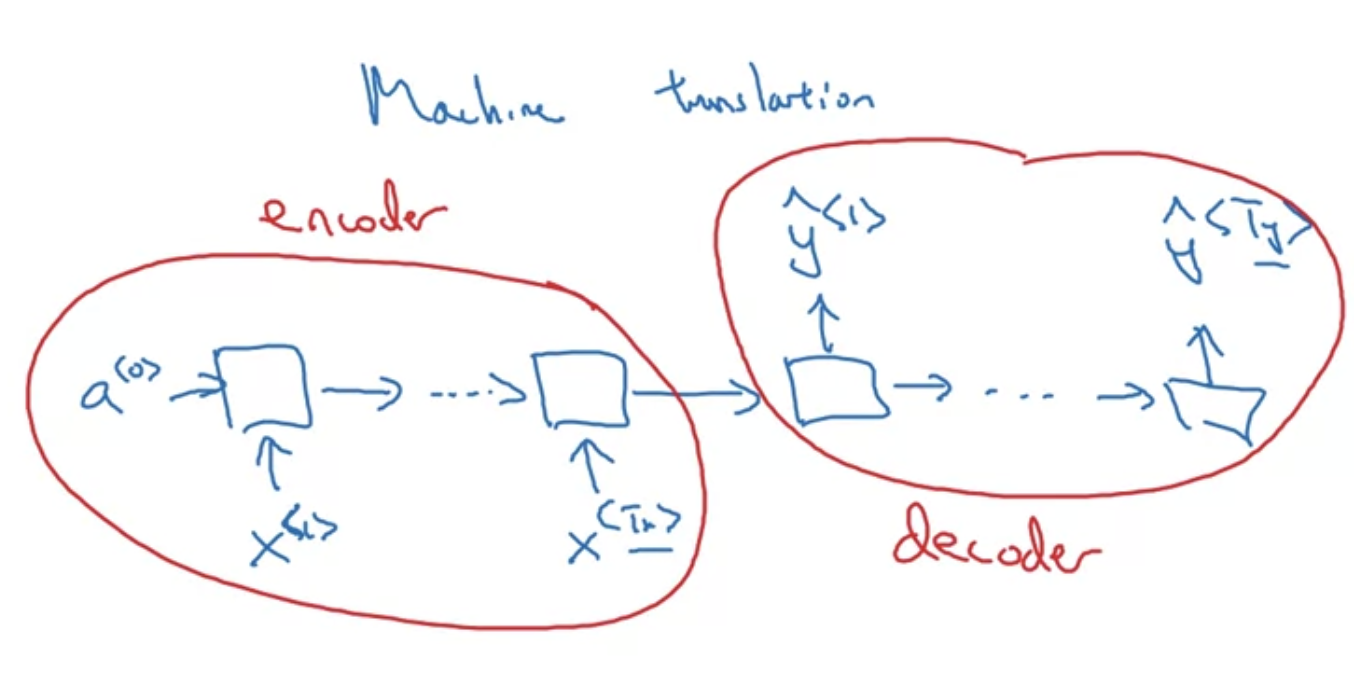
입력 encoder 와 출력 decoder 로 나눠서 볼 수 있음
[Summary of RNN types]

Language Model and Sequence Generation
Speech Recognition
- The apple and pair salad
- The apple and pear salad
--> 발음은 같지만 맥락상 후자가 맞음. 좋은 언어모델은 후자를 출력할 것이다.
각 문장에 대한 probability를 확인함으로써 출력할 수 있다
P(The apple and pair salad) = $3.2 \times 10^{-13}$
P(The apple and pear salad) = $5.7 \times 10^{-10}$
언어모델이 하는 것: 주어진 문장에 대한 확률
$P(sentence) = ? $
"if you were to pick up a random newspaper, a random email, or a random webpage, or listen to the next thing someone says, what is the chance that the next sentence you read somewhere out there in the world will be a particular sentence 'the appple and pear salad'?"
언어모델의 basic job:
input a sentence and estimate the probability of that particular sequence of words
$$P(y^{<1>}, y^{<2>}, \cdots, y^{<T_{y}>})$$
[Lanugage modelling with an RNN]
Training Set : large corpus of English text
"Cats average 15 hours of sleep a day"
-> $y^{<1>}$, $y^{<2>}$, $y^{<3>}$, $\cdots$
1) tokenize : 온점(.)도 토크나이징 할지는 경우에 따라 판단
2) mapping : 각 토큰들을 one-hot vector나 vocab의 인덱스로 맵핑
(경우에 따라) 3) <EOS> : end of sentence, 문장의 끝을 알려주는 토큰을 마지막에 더함
(vocab에 없는 단어가 있을 경우) 4) <UNK> : unknown word, vocab에 없는 토큰은 <UNK> 토큰으로 교체
[RNN model]
"Cats average 15 hours of sleep a day. <EOS>"
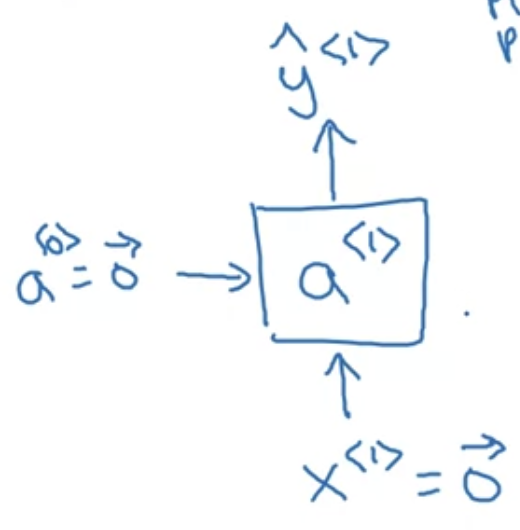
첫번째 스텝. $0$으로 이루어진 $a^{<0>}$, $x^{<1>}$ 를 입력하여 $a^{<1>}$ 계산.
Softmax 통과하면서 첫번째 단어가 10000개 단어(vocab의 크기) 중에서 "Cats"일 확률 $\hat{y}^{<1>}$ 을 출력한다.
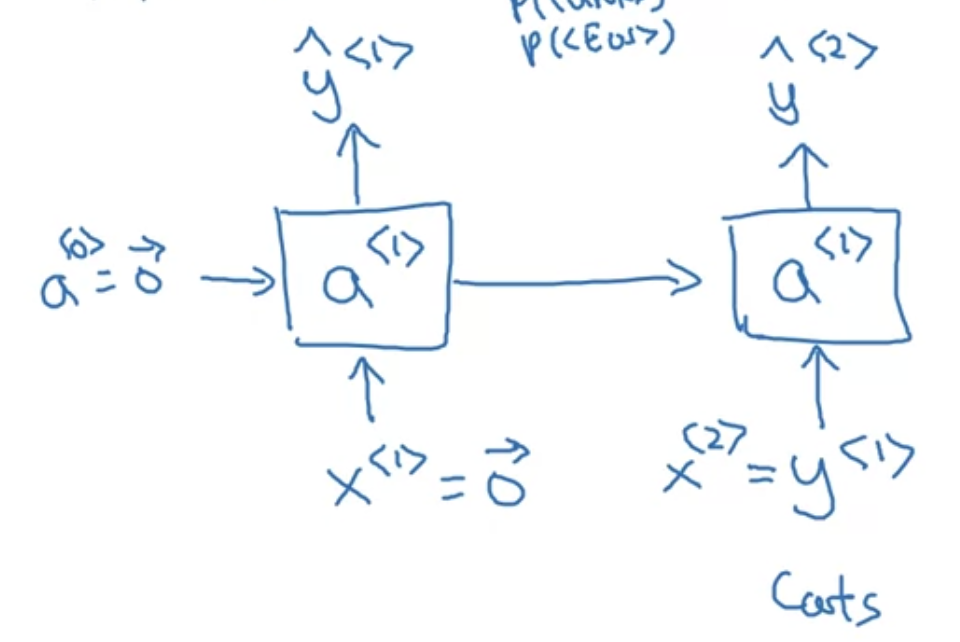
그 다음 스텝. $x^{<2>}$, 즉 $ y^{<1>}$(cats)를 입력하여 $a^{<2>}$ 계산.
Softmax 통과하면서, 주어진 단어가 "Cats"일 때 그 다음 단어가 "average"일 확률 $\hat{y}^{<2>}$ 을 출력한다.
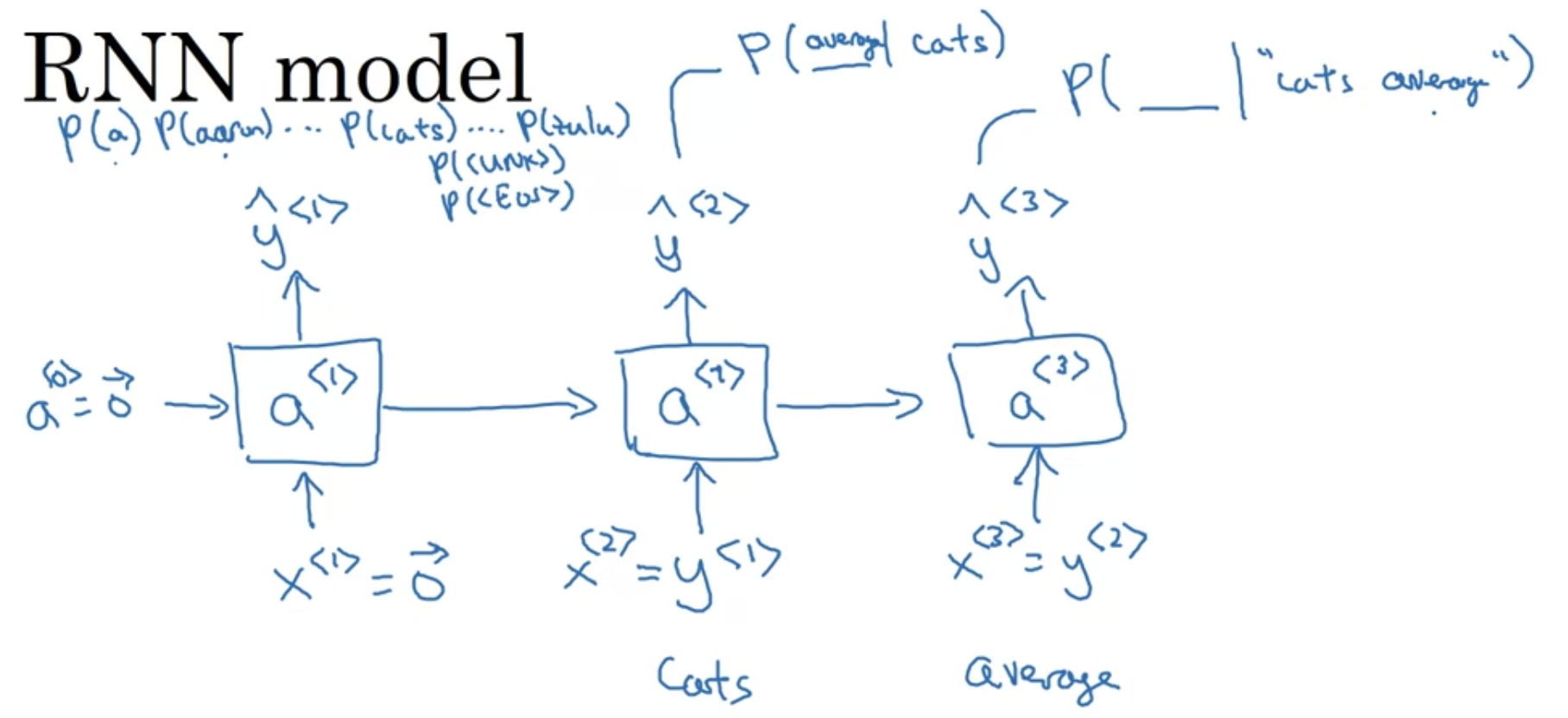
그 다음 스텝. $x^{<3>}$, 즉 $ y^{<2>}$(average)를 입력하여 $a^{<3>}$ 계산.
Softmax 통과하면서, 주어진 단어가 "Cats average"일 때 그 다음 단어가 "15"일 확률 $\hat{y}^{<3>}$ 을 출력한다.
같은 방식으로 반복
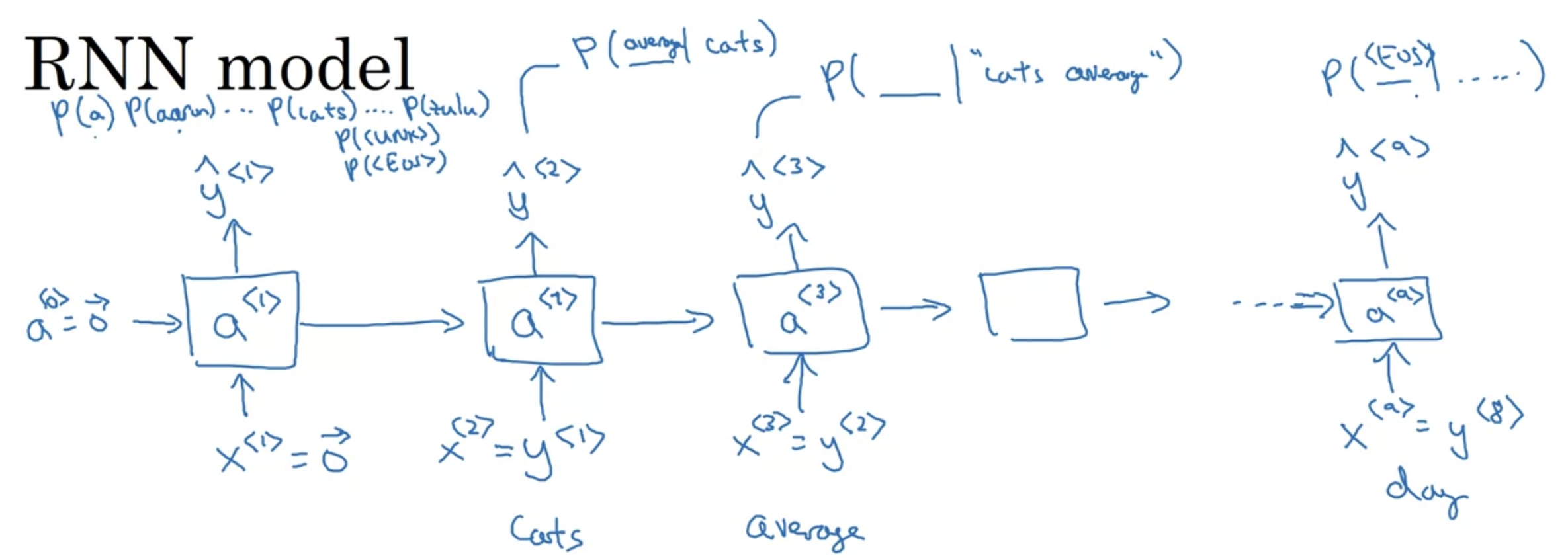
마지막 스텝. $x^{<9>}$, 즉 $ y^{<8>}$(day)를 입력하여 $a^{<9>}$ 계산.
Softmax 통과하면서, 주어진 단어가 "Cats average 15 hours of sleep a day"일 때 그 다음 토큰이 <EOS>일 확률 $\hat{y}^{<9>}$ 을 출력한다.
RNN은 연속된 단어가 주어졌을 때, 그 다음 단어의 분포를 예측하는. 왼쪽에서 오른쪽으로 한번에 한 단어를 예측하는 일을 수행한다.
cost function
$$L(\hat{y}^{<t>}, y^{<t>}) = - \sum_{i} y_{i}^{<t>} log \hat{y}_{i}^{<t>}$$
$$L = \sum_{<t>}L^{<t>}(\hat{y}^{<t>}, y^{<t>})$$
- 특정 스텝(time) $t$에서, 실제 단어가 $y^{<t>}$이고 softmax로 예측한 단어가 $\hat{y}^{<t>}$일
- softmax loss function
$$P(y^{<1>}, y^{<2>}, y^{<3>}) = P(y^{<1>})P(y^{<2>}|y^{<1>})P(y^{<3>}|y^{<1>}, y^{<2>})$$
- $y^{<1>}, y^{<2>}, y^{<3>}$로 이루어진 문장이 있을 때 probability를 구하는 식
Sampling Novel Sequences
[Sampling a sequence from a trained RNN]
모델이 무엇을 학습했나 확인하는 방식
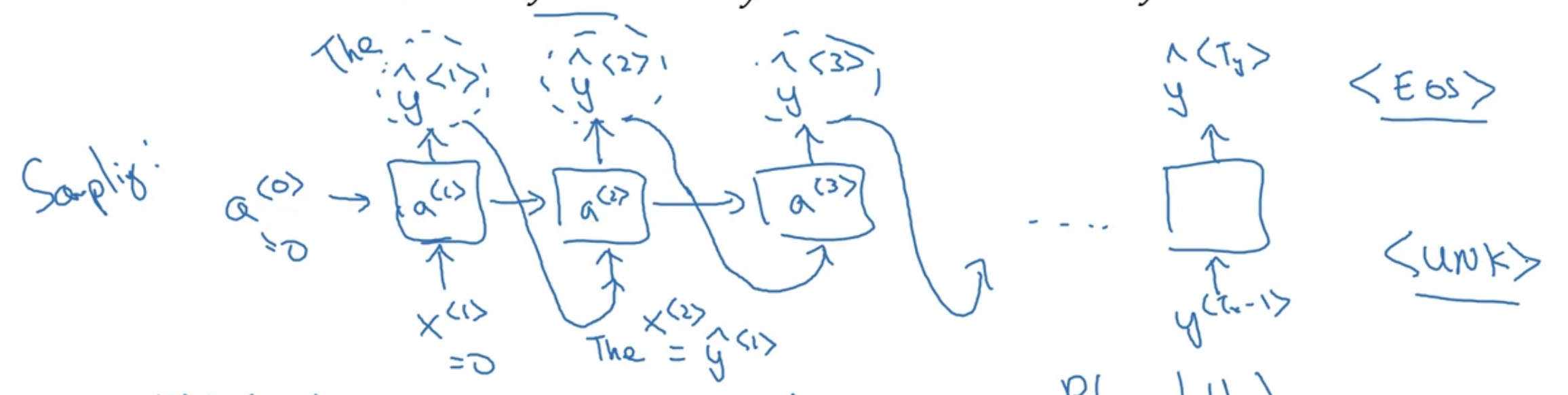
학습된 분포로부터 샘플링하여 새로운 sequences of word 를 생성한다
- (첫번째 timestep) 먼저 모델이 생성하고자 하는 첫번째 단어를 샘플링한다
- 이를 위해서는 학습할 때와 같이 0으로 이루어진 $x^{<1>}$와 0으로 이루어진 $a^{<0>}$를 입력한다
- 그 출력으로 softmax probability $\hat{y}^{<1>}$가 나온다
- 이 softmax 분포에 따라서 랜덤하게 샘플링한다
- softmax 분포: 첫번째 단어가 "a"일 확률($P(a)$), 첫번째 단어가 "aaron"일 확률($P(aaron)$), ..., 첫번째 단어가 "zulu"일 확률($P(zulu)$), 첫번째 단어가 "<UNK>"일 확률($P(<UNK>)$)
- 위 분포 벡터에 따라서 np.random.choice 로 샘플링
- (두번째 timestep) 직전 스텝에서 샘플링한 $\hat{y}^{<1>}$을 input으로 입력 -> $\hat{y}^{<2>}$ 출력
- (다음 timestep) 같은 식으로 반복
- (sequence 마지막) 어떻게 마지막인지 알 수 있을까?
- 만약 <EOS>이 vocab에 있다면 <EOS> 토큰이 생성될 때까지 계속 샘플링할 수 있음
- 만약 <EOS>이 vocab에 없다면 샘플 개수를 정해놓고 그만큼 timestep이 갔을 때 중단할 수 있음
- 샘플링 중 <UNK> 토큰이 생성될 수도 있음 - 이것이 싫다면 안 나올 때까지 resampling하면 됨
지금까지는 단어 단위(word-level) RNN 모델을 살펴봤는데, 문자 단위(character-level)로 설계할 수도 있음
- 이 경우 vocab = [a, b, c, ..., z, ' ', ., ,, ;, 0, 1, ..., 9, A, ..., Z] 형식으로 이루어짐
- $y^{<1>}$, $y^{<2>}$, $y^{<3>}$ 각각이 character가 됨
- 장점 : unknown 토큰에 대해 걱정하지 않아도 됨
- 단점 : 훨씬 긴 sequence를 가지기 때문에 단어단위 모델만큼 좋지 않음(단어 단위 모델은, 먼저 나온 단어들이 뒤 단어들에게 어떻게 영향을 주는지 long range dependencies를 포착하는 데 유리), computationally expensive
'인공지능 > DLS' 카테고리의 다른 글
| [5.2.] Introduction to Word Embeddings (0) | 2022.08.07 |
|---|---|
| [5.1.] Recurrent Neural Networks(3) (0) | 2022.08.06 |
| [5.1.] Recurrent Neural Networks(1) (0) | 2022.08.02 |
| [4.4.] Neural Style Transfer (0) | 2022.08.02 |
| [4.4.] Face Recognition (0) | 2022.08.02 |