
Probability and Bayes’ Rule
- probability, conditional probability
- Bayes' rule
- tweet classifier
probability 를 세는 방법? frequencies 를 카운트 한다
사건 A : 어떤 트윗이 positive으로 라벨링된다
P(A) : 사건 A의 확률
positive 트윗의 개수 / 전체 트윗의 개수
어떤 트윗이 negative로 라벨링될 확률은 1-P(A)
(*전체 트윗은 positive 아니면 negative 이다)
사건 B : 어떤 트윗이 단어 'happy'를 포함한다
P(B) : 사건 B의 확률
'happy'를 포함한 트윗의 개수 / 전체 트윗의 개수
'happy'를 포함하면서 positive로 분류된 트윗은? - 전체 말뭉치에서 사건A와 사건B의 교집합
Bayes’ Rule
"현재 겨울이고 캘리포니아에 있다는 사실이 주어졌을 때, 날씨가 어떨지 맞힐 수 있지?"
- conditional probability(조건부 확률)


전체 말뭉치가 아니라 'happy'를 포함하는 말뭉치들만 고려한다면 어떨까?
P(A|B) = P(positive|happy)
반대로, positive로 라벨링돈 말뭉치들만 고려한다면 어떨까?
P(B|A) = P('happy'|positive)
"사건 A가 이미 발생했음을 아는 상태에서 사건 B의 확률을 계산하는 것"
"집합 A의 어떤 요소를 볼 때, 그 요소가 집합 B에도 포함될 확률을 계산하는 것"

여기서 베이즈 정리를 유도할 수 있음
P(positive ∩ happy) = P(happy ∩ positive) 이므로

"사건 Y가 이미 발생했을 때 사건 X가 발생할 확률" = "사건 X가 이미 발생했을 때 사건 Y가 발생할 확률" x "확률 Y에 대한 확률 X의 비율"
--> 베이즈 정리
베이즈 정리는 조건부 확률의 수학적 정리일 뿐!
베이즈 정리를 활용해서, P(X|Y)를 구할 수 있음 - P(Y|X)와 P(X)/P(Y) 비율을 안다면!
Naïve Bayes Introduction
나이브 베이즈
- 지도학습의 한 예
- 로지스틱 회귀와 비슷한 점이 많음
왜 나이브?
- 분류에 사용하는 feature가 모두 independent하다고 여기기 때문
- 사실 현실에서는 그렇지 않음

- 빈도수를 체크함으로써 각 단어에 대해 조건부 확률을 구할 수 있게 됨
- 클래스 내에서 빈도 횟수를 확률로 나타냄

- 이렇게 표를 정리했을 때, 한 클래스의 모든 확률들을 더하면 1이 됨
각 클래스에서의 확률이 같거나 비슷한 경우를 체크해보기

실제로 감성과 관련 없는 단어들임 - 나머지 단어들은 관련이 있음
이 관련 있는 단어들이 감성 분류에 있어서 가중치(weight)를 가진다
*because의 경우? positive 말뭉치에서만 등장했기 때문에 negative의 조건부 확률은 0
이 경우에는 positive/negative 말뭉치끼리 비교할 수가 없으며 계산에 방해가 됨
--> smoothing probability function
[Naive Bayes inference condition rule for binary classfication]
실제 어떤 트윗을 분류한다고 해보자
"I am happy today; I am learning"

트윗의 모든 단어에 대해서, positive class에서의 확률을 negative class에서의 확률로 나눈다
이들을 모두 곱함
*vocab에 today가 없으므로 계산에 포함하지 않음

이 값이 1보다 크다 = 단어가 전체적으로 positive sentiment에 해당된다
--> 이 트윗은 positive 다
Laplacian Smoothing
어떤 단어의 다음에 올 단어의 확률을 계산하기
-> 두 단어가 순서대로 출현한 횟수를 세고, 첫번째 단어가 나타난 횟수로 나눈다
- 훈련셋에서 두 단어가 같이 출현한 적이 없다면? 확률은 0이 될 것임
-> 이 문제를 해결해야 함
[Laplacian Smoothing 라플라시안 스무딩]
확률이 0이 되어버리는 것을 방지하기 위함
어떤 클래스가 주어졌을 때 wi의 확률을 구하기 위해서는
그 클래스에 wi가 나타난 횟수를 해당 클래스의 전체 단어 횟수로 나눈다

확률함수를 스무딩하기 --> 살짝 변형한다

- 분자에 1을 추가해서 0이 되는 것을 방지함
- 분모에 사전 속 단어 갯수를 추가해서 분자에 1 추가한 것을 커버함
--> 이전과 마찬가지로 확률들을 모두 더하면 1이 됨
이 과정을 라플라시안 스무딩이라고 부른다
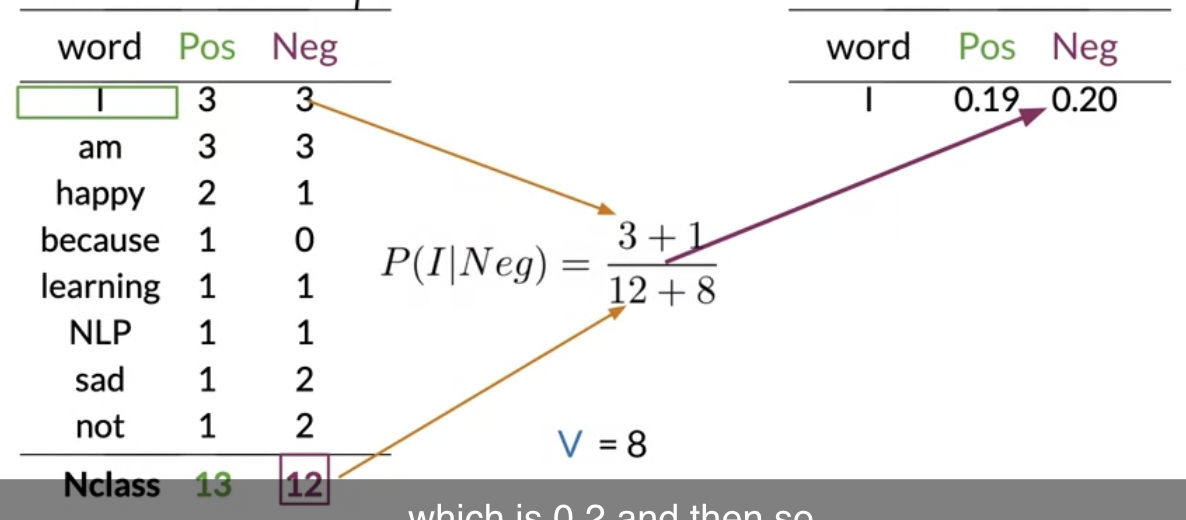
이전과 다르게 단어 because의 확률이 0이 아님을 볼 수 있음
Log Likelihood, Part 1
주어진 클래스에서의 확률끼리 나누면 ratio를 구할 수 있음

ratio의 범위

- ratio가 1이면 neutral, 1보다 커서 무한대로 갈 수 있는 positive, 1 미만의 양수인 negative
- positiviy, negativity 기반으로 단어를 필터링할 수 있음
(왠지 익숙할 텐데) 어떤 트윗의 감성을 분류할 때 아래 식을 사용했었음

1보다 크면 positive 였던 것으로.
--> 이것이 likelihood 다

(좌측) positive, negative 트윗의 비율은 prior ratio 이라고 한다. 이를 추가한다
불균형한 데이터셋의 경우 이 비율이 중요해짐 (현재 예시에서는 1:1 이므로 고려할 필요가 없음)
--> full Naive Bayes' formula for binary classification
[log likelihood]
나이브 베이즈 적용에 있어서 고려해야 할 것들
- 0과 1 사이 숫자들 간의 곱셈이 많음 --> numerical underflow의 위험
--> log 를 활용한다


즉 log(prior) + log(likelihood)
(우항) 말뭉치의 모든 unique words의 조건부확률의 비율들의 로그값을 모두 더한 값
[Calculating Lambda]

단어의 조건부확률의 비율의 로그값을 구하는 식을 Lambda 라고 부름
표 맨 오른쪽에는 람다 점수표가 생긴 것임
*람다는 로그값임을 기억
람다가 0이면 neutral (log 1), 양수면 positive, 음수면 negative(log ~1)
Log Likelihood, Part 2
log likelihood는 람다 점수표에서 찾아서 더하기만 하면 됨 (로그값)

단순 곱하기로 했을 때는 1보다 크고 작은 게 기준이었음
이제는 로그값이기 때문에 0보다 크고 작은 게 기준이 됨
(decision threshold)
