Training Naïve Bayes
경사하강법 없음. 그냥 출현횟수만 셀 것임.
1. 전처리
- 소문자화, 특수문자, 대명사 제거, 불용어 제거, 어간 분리, 토큰화
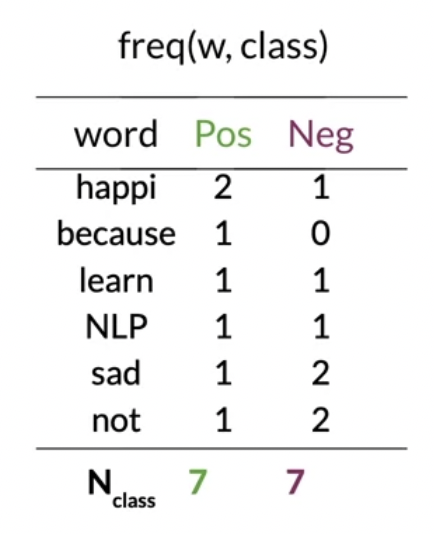
2. word count
- 클래스별로 출현횟수 정리한 사전 구축
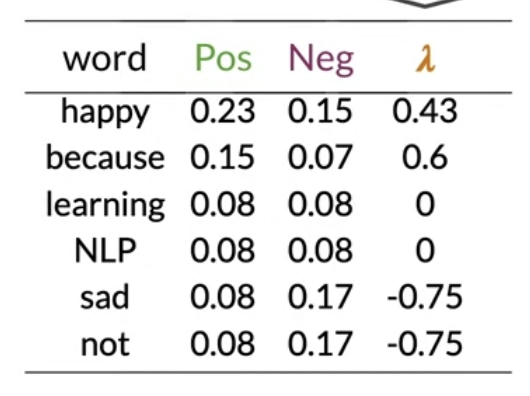
3. 조건부확률 계산 + 라플라시안 스무딩
4. 람다 계산
5. log prior 추정
- 클래스별 전체 트윗 개수로 비율 구한 후 log값 구함
(* 완전히 균형이 맞춰진 데이터셋에서 log prior는 0 이 됨)
Testing Naïve Bayes
- 훈련된 나이브 베이즈 모델로 새로운 트윗의 감정을 예측하기
- 람다 스코어표, log prior 활용
- 람다 스코어표를 모두 더한다
- 사전에 없는 새로운 단어는 neutral로 간주한다
- log prior 도 더한다
- 이 결과가 1보다 크면 긍정
훈련된 나이브 베이즈 모델의 성능 검증하기
Xval, Yval 준비
Xval 에 대해서 예측 시행

Yval 과 결과 비교하여 맞는 경우 1, 틀린 경우 0
이들을 모두 곱한 후 검증셋 개수로 나누면 됨 (로지스틱 회귀에서 한 것과 동일)
Applications of Naïve Bayes
나이브 베이즈 모델로 트윗의 감정을 분류한다는 것 =
클래스에서 단어들의 결합확률(joint probability)로써 각 클래스의 확률을 구하는 것
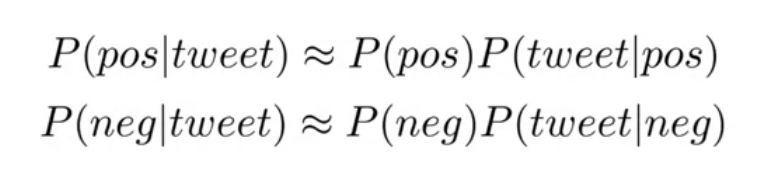
나이브 베이즈 정리는 이 두 확률의 ratio 임
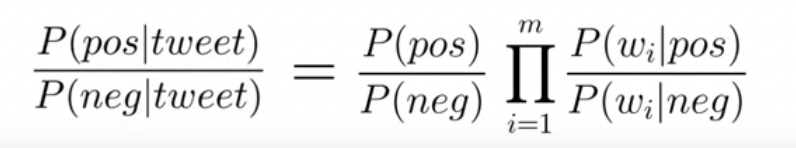
적용 사례
1. author identification
2. spam filtering
3. information retrieval (어떤 문서가 중요한지)
4. word disambiguation (동음이의어의 뜻을 분류)
Naïve Bayes Assumptions
assumptions underlying the naive bayes method
[independence of words in a sentence]
"It is sunny and hot in the Sahara desert"
나이브 베이즈에서는 단어들끼리 독립적이라고 가정하지만,
sunny와 hot만 해도 같이 등장하는 경우가 많음
또 두 단어는 사하라 사막을 설명하고 있음
--> 단어 간의 독립성이 보장되지 않음
--> 각 단어들의 조건부확률을 under/overestimate할 위험이 있음
"It's always cold and snowy in __."
__를 채울 때 spring, summer, fall, winter 들로부터 동일한 확률을 계산하게 될 수 있음 ❓
[relative frequency in corpus]
학습 말뭉치의 분포에 의존하고 있음
예를 들어 트위터만 해도 긍정적인 트윗이 더 많이 나타남 (부정적인 트윗은 banned 당한 경우가 많아서)
그렇게 되면 optimistic 하거나 pessimistic한 모델이 탄생할 수 있음
Error Analysis
[전처리 문제]
- ':('와 같은 특수문자가 제거 되었을 때
[단어 순서]
"This is not good, because your attitude is not even close to being nice"
--> [good, attitude, close, nice] ?!
[adversarial attacks]
반어법, 아이러니, 완곡어법